图像降噪专用,不解释。
算法描述:
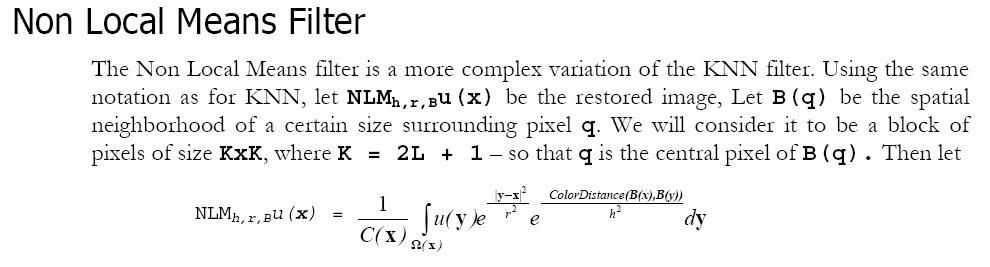

超慢的方法,处理每个像素的算法复杂度与处理半径的关系为O(N^4)。
偷懒一下加快算法:

代码(写成了线程函数模式,以便多线程处理,NOISE为降噪强度,LERPC为lerp系数): #include "stdafx.h"
#include <cmath>
#define NLM_WINDOW_RADIUS 3
#define NLM_BLOCK_RADIUS 3
#define NLM_WINDOW_AREA ((2 * NLM_WINDOW_RADIUS + 1) * (2 * NLM_WINDOW_RADIUS + 1))
#define INV_NLM_WINDOW_AREA (1.0f / (float)NLM_WINDOW_AREA)
#define NLM_WEIGHT_THRESHOLD 0.10f
#define NLM_LERP_THRESHOLD 0.10f
#define BLOCKDIM_X 8
#define BLOCKDIM_Y 8
__inline unsigned long vecLen(unsigned long p1, unsigned long p2)
{
unsigned char *a = (unsigned char *)&p1;
unsigned char *b = (unsigned char *)&p2;
return ((b[0] - a[0]) * (b[0] - a[0])
+ (b[1] - a[1]) * (b[1] - a[1])
+ (b[2] - a[2]) * (b[2] - a[2]));
}
/*
__inline float lerpf(float a, float b, float c)
{
return a + (b - a) * c;
}
*/
__inline unsigned long lerpf(unsigned long a, unsigned long b, long c)
{
return a + (b - a) * c / 65536;
}
__inline unsigned long tex2D(unsigned long *image, int p, int h, int x, int y)
{
if(x < 0)
x = 0;
else if(x >= p)
x = p - 1;
if(y < 0)
y = 0;
else if (y >= h)
y = h - 1;
return image[y * p + x];
}
#define NOISE 0.25f
#define LERPC 0.15f
UINT AFX_CDECL CPUFastNLMThread(LPVOID param)
{
unsigned long *p = (unsigned long *)param;
unsigned long *image = (unsigned long *)p[0];
unsigned long pitch = p[1];
unsigned long pitch4 = p[1] / 4;
unsigned long width = p[2];
unsigned long height = p[3];
unsigned long y_amount = p[4];
unsigned long y_start = p[5];
unsigned long *image_out = (unsigned long *)p[6];
float Noise = 1.0f / (NOISE * NOISE);
float lerpC = LERPC;
long bx, by, tx, ty;
for(by = y_start; by < y_start + y_amount; by += BLOCKDIM_Y)
{
for(bx = 0; bx < width; bx += BLOCKDIM_Y)
{
// float fWeights[BLOCKDIM_X * BLOCKDIM_Y];
long fWeights[BLOCKDIM_X * BLOCKDIM_Y];
for(ty = 0; ty < BLOCKDIM_Y; ty ++)
for(tx = 0; tx < BLOCKDIM_X; tx ++)
{
long x = bx + tx;
long y = by + ty;
long cx = bx + NLM_WINDOW_RADIUS;
long cy = by + NLM_WINDOW_RADIUS;
if((x < width) && (y < height))
{
//Find color distance from current texel to the center of NLM window
// float weight = 0;
long weight = 0;
for(int n = -NLM_BLOCK_RADIUS; n <= NLM_BLOCK_RADIUS; n ++)
for(int m = -NLM_BLOCK_RADIUS; m <= NLM_BLOCK_RADIUS; m ++)
weight += vecLen(tex2D(image, pitch4, height, cx + m, cy + n), tex2D(image, pitch4, height, x + m, y + n));
//Geometric distance from current texel to the center of NLM window
float dist = (float)((tx - NLM_WINDOW_RADIUS) * (tx - NLM_WINDOW_RADIUS) + (ty - NLM_WINDOW_RADIUS) * (ty - NLM_WINDOW_RADIUS));
//Derive final weight from color and geometric distance
// weight = exp(-(weight / 65536.0f * Noise + dist * INV_NLM_WINDOW_AREA));
//Write the result to memory
// fWeights[ty * BLOCKDIM_X + tx] = weight;
fWeights[ty * BLOCKDIM_X + tx] = exp(-(weight / 65536.0f * Noise + dist * INV_NLM_WINDOW_AREA)) * 65536;
}
}
for(ty = 0; ty < BLOCKDIM_Y; ty ++)
for(tx = 0; tx < BLOCKDIM_X; tx ++)
{
long x = bx + tx;
long y = by + ty;
if((x < width) && (y < height))
{
//Normalized counter for the NLM weight threshold
// float fCount = 0;
long fCount = 0;
//Total sum of pixel weights
// float sumWeights = 0;
long sumWeights = 0;
//Result accumulator
// float clr[3] = {0, 0, 0};
long clr[3] = {0, 0, 0};
int idx = 0;
//Cycle through NLM window, surrounding (x, y) texel
for(long i = -NLM_WINDOW_RADIUS; i <= NLM_WINDOW_RADIUS + 1; i ++)
for(long j = -NLM_WINDOW_RADIUS; j <= NLM_WINDOW_RADIUS + 1; j ++)
{
//Load precomputed weight
// float weightIJ = fWeights[idx ++];
long weightIJ = fWeights[idx ++];
//Accumulate (x + j, y + i) texel color with computed weight
long clrIJ = tex2D(image, pitch4, height, x + j, y + i);
clr[0] += (clrIJ & 0xff) * weightIJ;
clr[1] += ((clrIJ >> 8) & 0xff) * weightIJ;
clr[2] += ((clrIJ >> 16) & 0xff) * weightIJ;
//Sum of weights for color normalization to [0..1] range
sumWeights += weightIJ;
//Update weight counter, if NLM weight for current window texel
//exceeds the weight threshold
// fCount += (weightIJ > NLM_WEIGHT_THRESHOLD) ? INV_NLM_WINDOW_AREA : 0;
fCount += (weightIJ > 6553) ? 1337 : 0;
}
//Normalize result color by sum of weights
/*
sumWeights = 1.0f / sumWeights;
clr[0] *= sumWeights;
clr[1] *= sumWeights;
clr[2] *= sumWeights;
*/
clr[0] /= sumWeights;
clr[1] /= sumWeights;
clr[2] /= sumWeights;
//Choose LERP quotent basing on how many texels
//within the NLM window exceeded the weight threshold
// float lerpQ = (fCount > NLM_LERP_THRESHOLD * 65536) ? lerpC : 1.0f - lerpC;
long lerpQ = (fCount > 6553) ? 13107 : 52429;
//Write final result to memory
unsigned long clr00 = image[y * pitch4 + x];
clr[0] = lerpf(clr[0], clr00 & 0xff, lerpQ);
clr[1] = lerpf(clr[1], (clr00 >> 8) & 0xff, lerpQ);
clr[2] = lerpf(clr[2], (clr00 >> 16) & 0xff, lerpQ);
image_out[y * pitch4 + x] = ((unsigned char)clr[0]) | ((unsigned char)clr[1] << 8) | ((unsigned char)clr[2] << 16);
}
}
}
}
return 0;
}


































200字以内,仅用于支线交流,主线讨论请采用回复功能。