


现在表局已经人均GPT写程序了。照这个速度下去,中外之间很快就会有产业革命级别的差距了。
加载中
加载中
表情图片
评为精选
鼓励
加载中...
文件下载
加载中...
笔者对于GPT的使用,就像是绝大多数同学一样,是从文章代写开始的。笔者是一个兴趣爱好相当广泛的人,虽然是商学学士和农经硕士,但心中总有工程师/物理学家/程序员的梦,这也是笔者试图利用ChatGPT作为编程工具和学习工具的契机。最早使用GPT3.5是2023年3月的事,当时大火的热度其实已经过了巅峰了,大部分非专业的人群,尤其是媒体人,当时就已经对此类工具的报道有所疲倦了,笔者还是抱着试试看的态度,付费购买了境内某平台的GPT3.5接口开始试用(之后会聊到这一点,相当坑)。在无聊的实习生活中,GPT3.5给我带来了很大的乐趣,我的第一个python程序,第一个实用的51单片机C语言程序,都是通过GPT3.5完成的,但局限性相当明显,在试图使用GPT3.5进行一些复杂的程序实现工作,以及学习一些深入的数理知识时,GPT3.5开始明显的胡编乱造,被早期使用者饱受诟病的文献扯谎问题也十分突出。可以说,当时的GPT,除了作为高级版八股文生成器,以及少数技术宅的娱乐玩具以外,很难胜任任何高附加值的工作,甚至也不能作为完美的程序模块生成器(但就笔者编程小白的水平来说,上手已经比各类python大模型辅助编程插件要容易得多了)。
真正引人注目的变化是从GPT4,以及其后数次大更新带来的。笔者已经不记得从何时起,GPT4在文章生成以外的一系列功能性使用上出现了飞跃式的进步,但可以明确的是,在笔者2023年7月开学起,GPT4就已经可以帮助笔者解决相当一部分硕士课程面临的问题了,主要集中在对于统计编程软件R studio的学习和使用上。不过本文希望讨论的主要内容,依然是GPT4.0在笔者兴趣爱好领域的一系列求知过程以及对知识的实践层面上的帮助。首先给出本文重点的两个实例,窥见GPT4的强大之处。
Stock Price Model based on Geometric Brownian Motion (基于几何布朗运动的股票价格模型)

这是一个在金融数学中最简单最常用的随机微分方程模型(Stochastic Differential Equation),被广泛用于BS模型(一种无派息欧式期权定价模型). 在这张展示图中的,除了参数以外所有程序行,都是通过与GPT4循序渐进的学习和交流生成的,也包括较为清晰易懂的注释.
2. RLC Solenoid Magneticfield Calculator (RLC中的螺线管磁场计算器)


这是笔者希望构建一个python的初步电磁炮仿真程序的尝试, 通过输入RLC电路模型中的各项参数, 计算出线圈中心的磁场强度, 并绘出中心磁场强度在时间上变化的曲线. 图中展示的程序全部都是由GPT4.0生成, 相比1中展示的几何布朗运动模型, 此RLC模拟程序还多了运行开始后主动询问各项参数的程序行, 使得将其打包为即开即用的exe程序提供了便利(当然python运行库打包出的exe程序将会是又大又慢的).
以上是一些介绍, 下文中将对于如何通过ChatGPT对这些内容进行学习和利用进行详细的讲解, 也欢迎在本文涉及的领域专业的大佬提出建议和批评, 帮助笔者进一步学习深入.
首先对于第一个实例, 基于几何布朗运动的股票价格模型, 进行阐述和解读. 笔者是2018年入市的新股民, 作为新鲜的韭菜总有一些不着边际的想法, 笔者并非是金融数学专业的学生, 但的确数年来都没能跳出经管类的大圈, 所以本着一贯的对于数学领域的叶公好龙, 以及对于金钱的贪婪, 笔者尝试通过ChatGPT对金融数学, 尤其是股票/期货市场的价格模型进行入门的学习. 而首当其冲的数学方法, 就是在统计物理和混沌/复杂系统中也有普遍应用的随机微分方程. 这一方法对于甚至没有系统学习过理科高数的笔者来说可以说是一窍不通的, 但通过与GPT4之间循序渐进的学习交流, 窥见美感并不难做到.
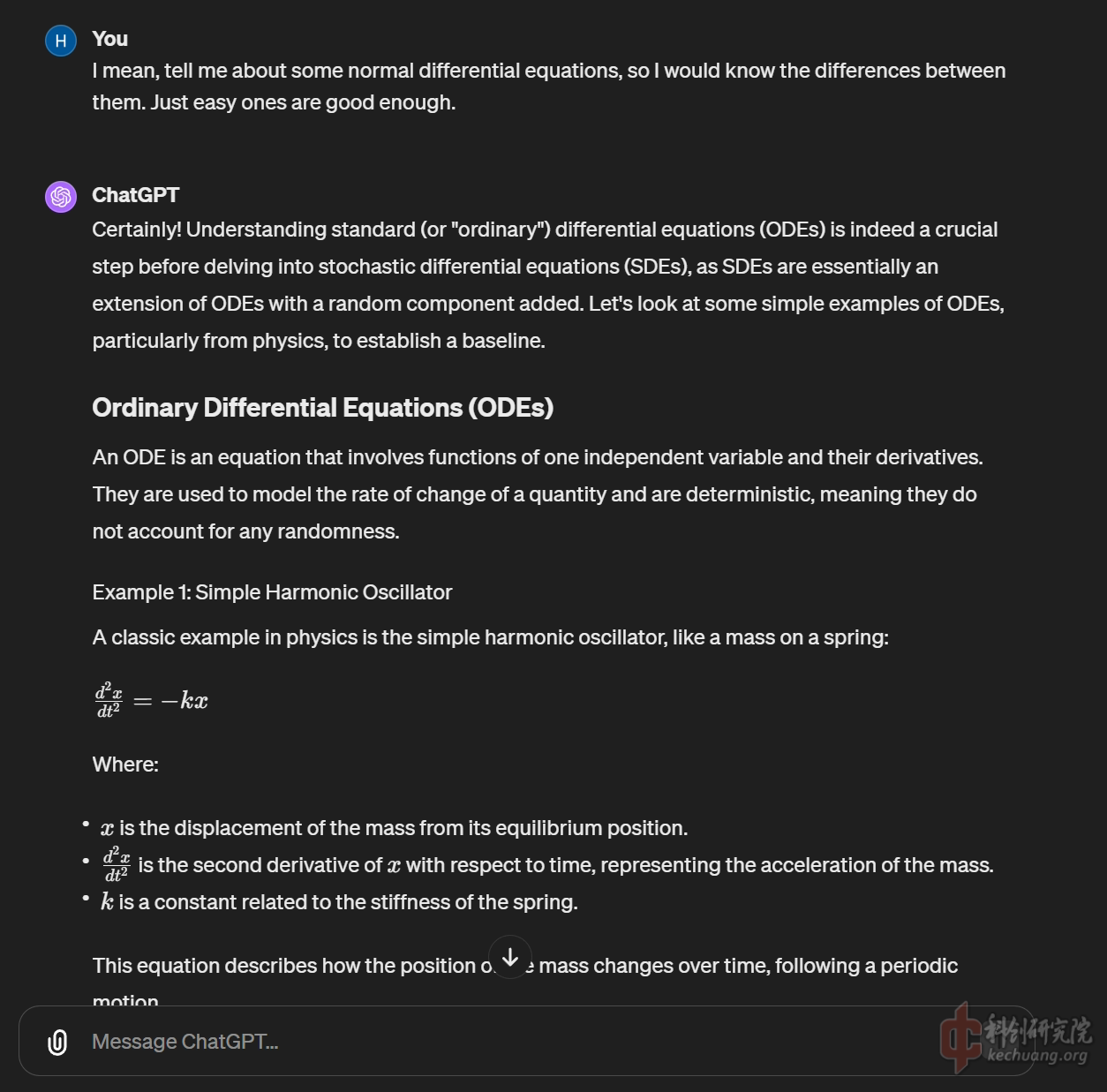
一些复习工作, 通过对弹簧振子简谐运动进行复习, 捡起为数不多的关于常微分方程的知识, 可以发现, GPT4依然会犯一些小错误,比如在此方程中忽略了振子的质量m.

通过卖关子的方式指出它存在问题, GPT4可以做到很好的自我纠错, 敏锐发现了缺少质量参数.
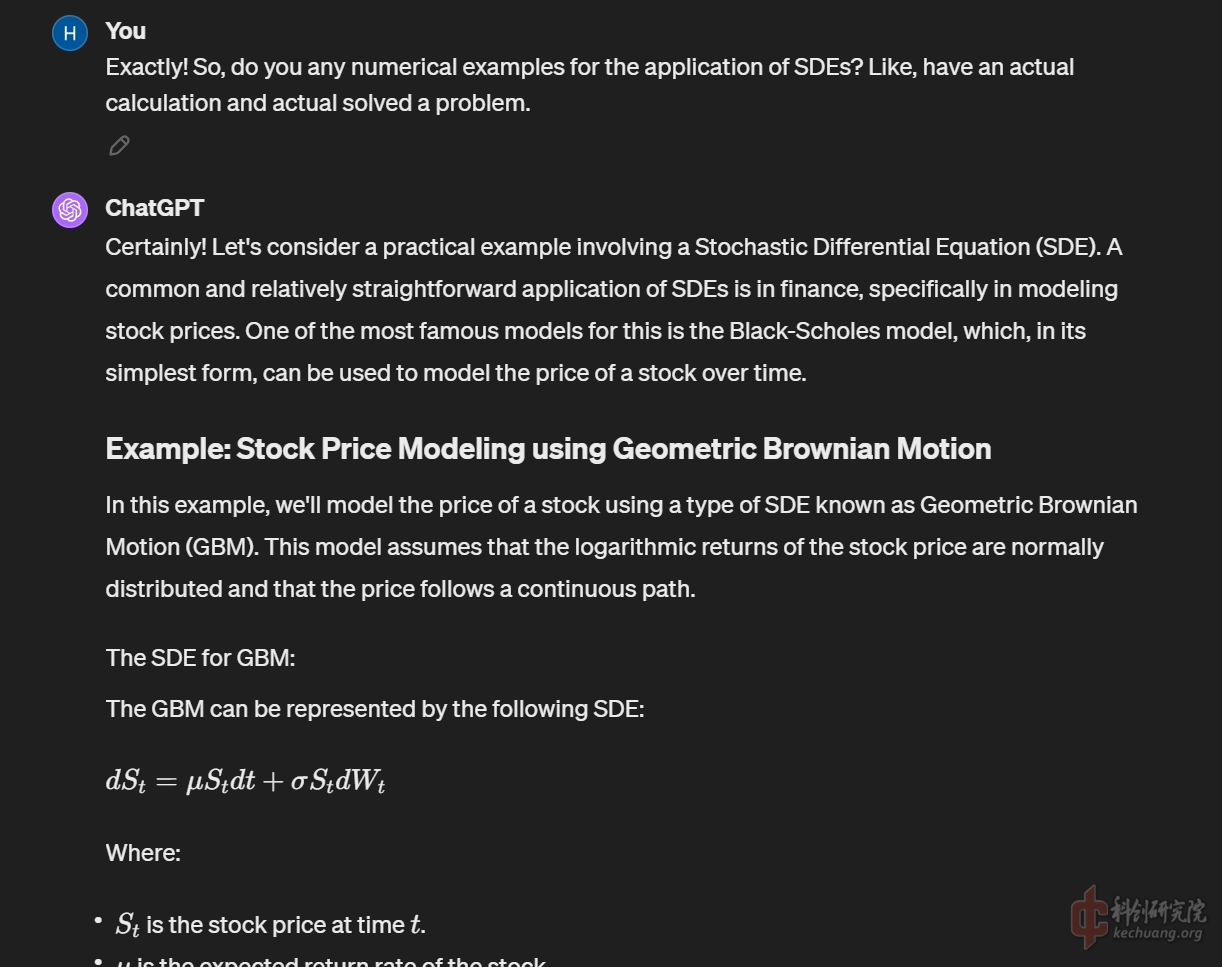
切入正题, 询问有关Stochastic Differential Equation的知识, 很巧, GPT4.0第一反应就是基于几何布朗运动的股价模型, 看来它的训练库里关于这种数学方法的部分还是金融数学领域的文献更多一些.
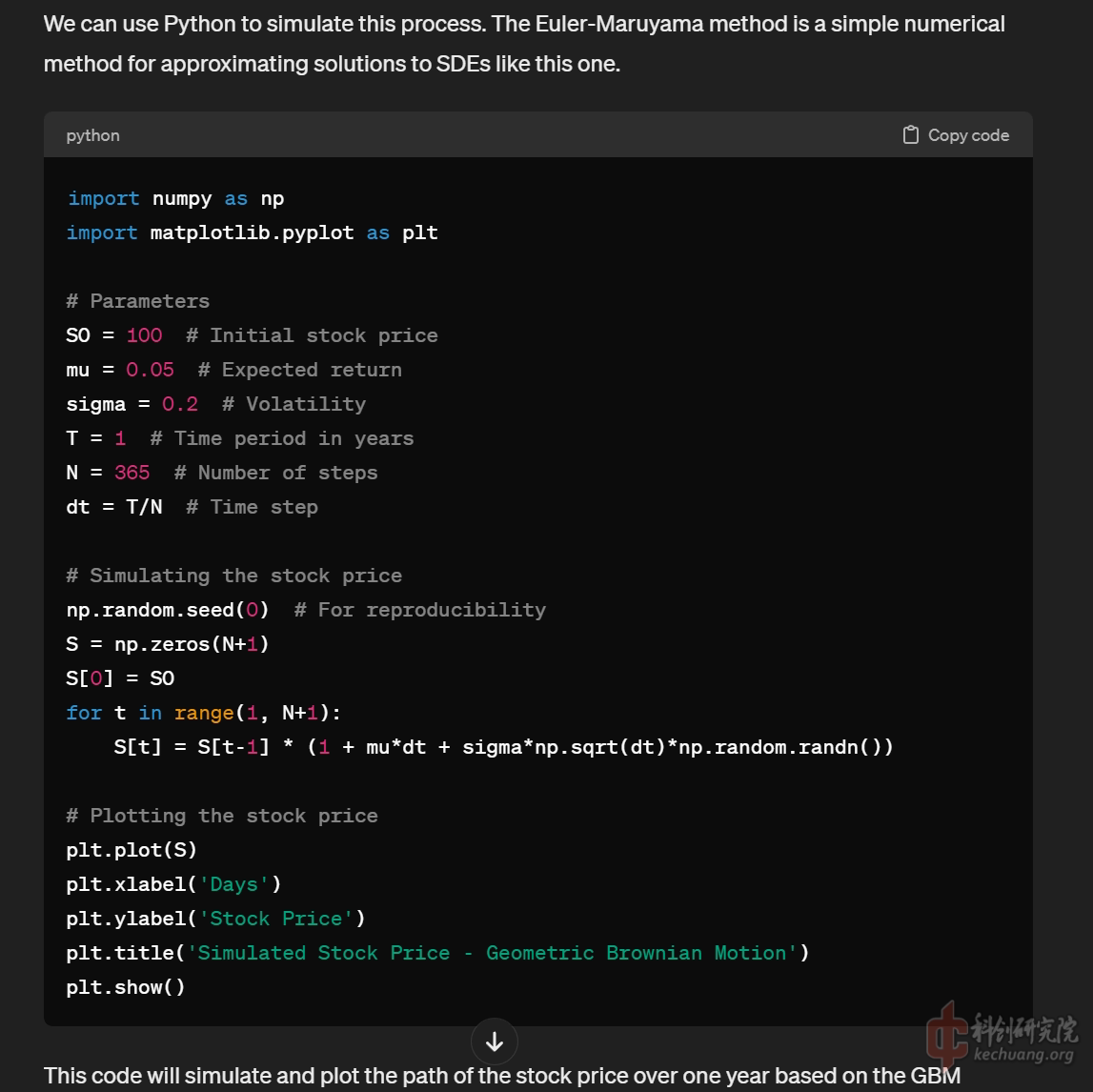
在给出了一个完全不需要纠错的简单模型程序后, 我进一步询问了其中涉及到的一些参数的具体市场意义的问题, GPT非但一一详细解答, 还进一步补充了这些参数可能可以如何通过历史数据获取的问题, 这让我那悬着担心自己需要长脑子才能学习这些知识的心终于可以放下了.
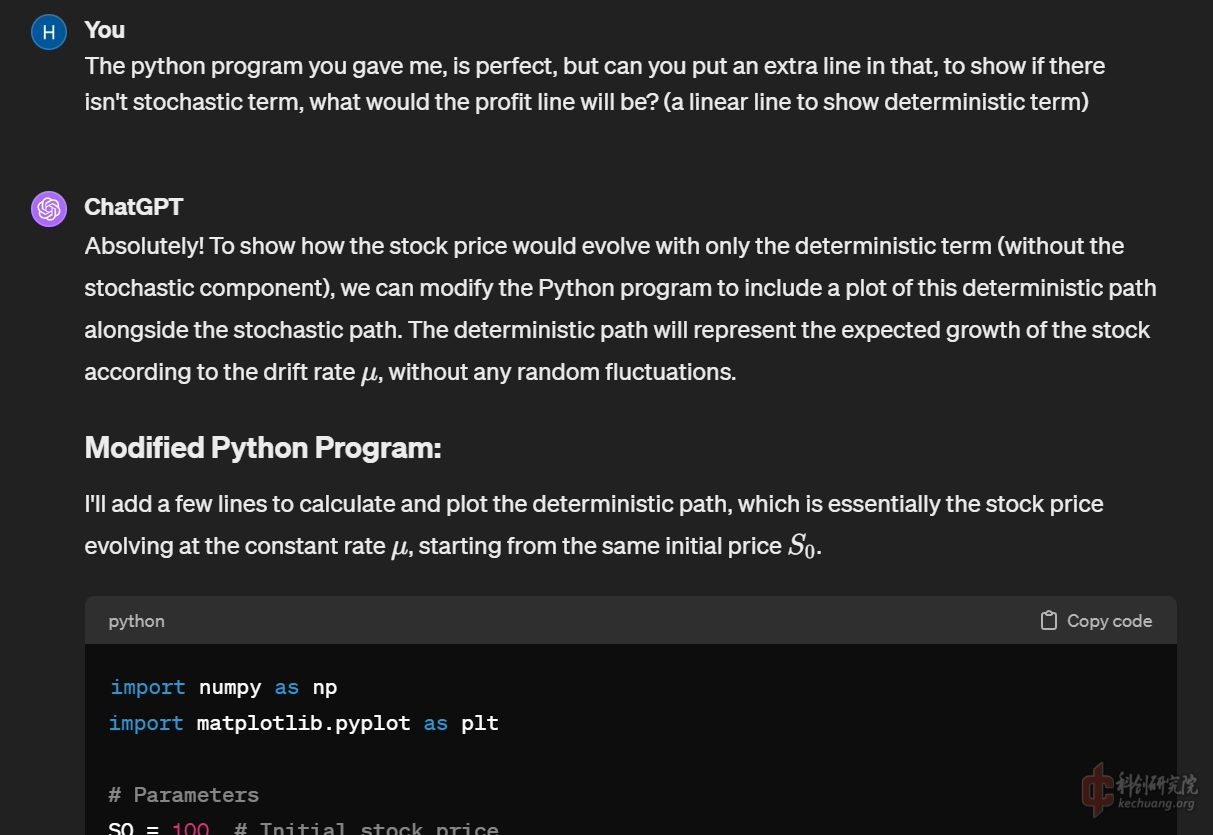

还要求GPT帮忙添加了一些额外的图示功能, 显示随机微分方程中单纯对流项的直线, 以及由扩散项的随机参数在时间演化上的误差累积构成的正态分布区间.
值得注意的是, 本实例中的尝试, 首先通过吟唱术式:
'Please pretend to be a mathematician who is good at probability theory, especially stochastic differential equation, and also know about python programming and R studio programming. Answer me some questions in a step by step approach (I only know some simple calculus, no more than U.S. AP calculus).'
限定了AI生成内容的大范围, 以确保生成内容的专业性, 以及更加个性化根据个人实际情况出发的教学方式. 经实测相比起直接吟唱正式内容的咒语可以少走弯路.
除此以外, 热身后的正式内容(其实还有很多很多, 只是为了节省读者时间, 不作更多描述), 需要以由简入难, 由少至多的方式, 通过谨慎揣摩吟唱逻辑的方式, 缓慢堆砌, 因为实测中, 如果有语义模糊的吟唱, 很可能会导致GPT在生成一段'偏义'内容后, 导致整个法术结构崩溃. 通常这种情况笔者会抹除所有对话从头再来, 因为试图通过一系列进一步的术式限定来将主要内容拉回正轨, 往往其实会导致最终构成一个臃肿的弗兰肯斯坦式的怪物.
首先对于第一个实例, 基于几何布朗运动的股票价格模型, 进行阐述和解读. 笔者是2018年入市的新股民, 作为新鲜的韭菜总有一些不着边际的想法, 笔者并非是金融数学专业的学生, 但的确数年来都没能跳出经管类的大圈, 所以本着一贯的对于数学领域的叶公好龙, 以及对于金钱的贪婪, 笔者尝试通过ChatGPT对金融数学, 尤其是股票/期货市场的价格模型进行入门的学习. 而首当其冲的数学方法, 就是在统计物理和混沌/复杂系统中也有普遍应用的随机微分方程. 这一方法对于甚至没有系统学习过理科高数的笔者来说可以说是一窍不通的, 但通过与GPT4之间循序渐进的学习交流, 窥见美感并不难做到.
一些复习工作, 通过对弹簧振子简谐运动进行复习, 捡起为数不多的关于常微分方程的知识, 可以发现, GPT4依然会犯一些小错误,比如在此方程中忽略了振子的质量m.
通过卖关子的方式指出它存在问题, GPT4可以做到很好的自我纠错, 敏锐发现了缺少质量参数.
切入正题, 询问有关Stochastic Differential Equation的知识, 很巧, GPT4.0第一反应就是基于几何布朗运动的股价模型, 看来它的训练库里关于这种数学方法的部分还是金融数学领域的文献更多一些.
在给出了一个完全不需要纠错的简单模型程序后, 我进一步询问了其中涉及到的一些参数的具体市场意义的问题, GPT非但一一详细解答, 还进一步补充了这些参数可能可以如何通过历史数据获取的问题, 这让我那悬着担心自己需要长脑子才能学习这些知识的心终于可以放下了.
还要求GPT帮忙添加了一些额外的图示功能, 显示随机微分方程中单纯对流项的直线, 以及由扩散项的随机参数在时间演化上的误差累积构成的正态分布区间.
值得注意的是, 本实例中的尝试, 首先通过吟唱术式:
'Please pretend to be a mathematician who is good at probability theory, especially stochastic differential equation, and also know about python programming and R studio programming. Answer me some questions in a step by step approach (I only know some simple calculus, no more than U.S. AP calculus).'
限定了AI生成内容的大范围, 以确保生成内容的专业性, 以及更加个性化根据个人实际情况出发的教学方式. 经实测相比起直接吟唱正式内容的咒语可以少走弯路.
除此以外, 热身后的正式内容(其实还有很多很多, 只是为了节省读者时间, 不作更多描述), 需要以由简入难, 由少至多的方式, 通过谨慎揣摩吟唱逻辑的方式, 缓慢堆砌, 因为实测中, 如果有语义模糊的吟唱, 很可能会导致GPT在生成一段'偏义'内容后, 导致整个法术结构崩溃. 通常这种情况笔者会抹除所有对话从头再来, 因为试图通过一系列进一步的术式限定来将主要内容拉回正轨, 往往其实会导致最终构成一个臃肿的弗兰肯斯坦式的怪物.
然后是第二个实例, RLC中的螺线管磁场计算器, 这事实上是笔者不成功的尝试中诞生的一个还算完善的中间产物. 笔者的思路是: 首先通过涵盖电容和线圈参数的LC振荡电路模型, 过渡到带电阻的RLC模型(一开始并不是这个步骤,而是直接描述需要的RLC电路模型,结果相当失败,所以进行了任务拆分,一次成功), 再通过RLC模型中输出的电流I在t上的值, 通过毕奥-萨法尔定律计算线圈中心的磁场场强B, 从而得到一个原点磁场强度B在t上的时变情况, 再通过理想的平方反比情况, 计算距离原点为d的理想圆环电枢在截面通量dΦ/dt的情况, 从而得到电枢感应电流dI/dt, 从而进一步计算在任意d时电枢受力的情况, 进而进一步推广到任意时刻的电枢受力, 从而可以进一步得到积分求出动能解. 我站在业余的角度是认为这个思路简直是完美的, 但不知道是我的吟唱方法有误, 还是真的现在的GPT还难以直接通过物理原理的描述排列出微积分式, 总之这一思路推进到dB/dt就完全卡死了, 在原本最接近成功的一次施法中, 也因为笔者的吟唱失误, 导致了上文中提及的"弗兰肯斯坦现象". 现在笔者头很痛, 可能是要长脑子了, 计划接下来使用手打微分方程直接喂给GPT, 看看是否可以解决这个思路中面临的一些过于跳跃的问题(当然也有可能因为开学而先暂时搁置这一小课题).

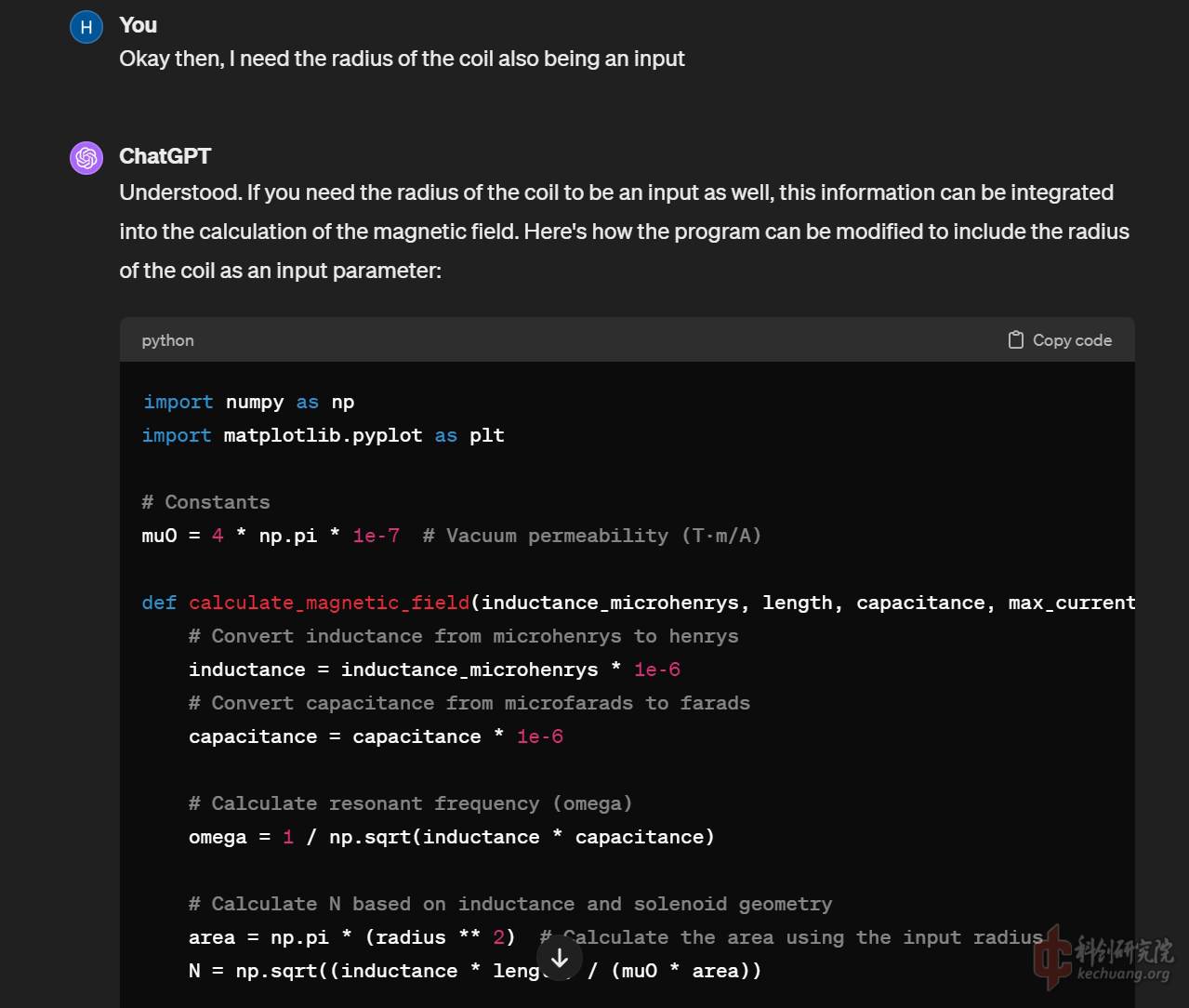
可以看到, 只要对于任务的切割足够严谨和细致, 就可以逐步推进程序的完善. 此实例因为不能算完全成功, 所以篇幅就点到为止, 对于这个小课题如有兴趣, 可以在科创论坛的qq电炮群找到笔者(北泽居士汉昏侯), 欢迎一起探索和讨论, 笔者较为专精的业余兴趣爱好依然是一如既往的电磁炮.
结论: 本来不想单独开一个总结部分, 毕竟是漫谈, 但是想了想还是单独拿出来讲一讲笔者个人对于GPT4这一顶尖大语言模型的现状的看法. 它在专业领域的表现可以说, 并不需要和3.5相比, 就可以说是惊艳了. 笔者现在的硕士学位攻读的是农业经济学方向, 在研一的一些农学通识课的小测, 以及日常的学习中, GPT4也可以稳定做到9成的正确率, 少数出错也大多是掉进了多选的迷惑项里. 可以说哪怕是对于农学这样相对小众的学术领域中, GPT4对于专业知识的拿捏也是足够准确了(毕竟没人会完全只靠GPT学习吧!). 当然, 从大语言模型的机制来看, 这说明的恰恰是OpenAI在训练它的产品时对于库的精耕细作, 在神经网络算法已经卷(积)了几十年的今天, 也许这恰恰说明了一个优秀的大语言模型背后, 真正的支撑力量其实是人类自身的智慧结晶.
OpenAI虽然目前还在巨额亏损, 但笔者作为新鲜的韭菜始终主观意愿上相信它未来的发展. 笔者也希望身边的朋友们, 互联网上的同好们, 也都能真正参与到这一场人工智能的热潮中来, 亲身体验GPT, 以及它延伸出的数不胜数, 涵盖从生活到学习到工作方方面面的, 优秀的AI产品.
关于在境内的时候, 第三方平台的"代理服务"的问题, 这似乎已经在国内形成了一套"灰色产业链", 不论付费的还是免费但看广告的, 层出不穷, 它的经营模式无非就是使用由许可的账号的API去经营一个中介交流, 通过广告流量或额外支取费用变现. 但它事实上对正常用户已经间接造成了困扰. OpenAI有段时间会大量封禁使用中文的用户, 需要漫长的申诉流程才能解封, 并且据说, 不排除二封的可能. 这种情况, 笔者个人认为是代理商的单一账号过多的访问, 使得OpenAI起了疑心(很遗憾他们猜对了), 从而发挥了Low Context文化环境一贯的神经大条, 掀起了一段时间的封禁浪潮(最近好像不听说了). 对于这个问题, 笔者主张理性看待, 因为他们客观上对这一重要的前卫工具在简中社区的推广起到了桥梁作用; 但还是希望有条件的朋友可以拥有自己的私人账号使用GPT, 考虑到训练库本身的来源是英文占绝大多数的海外论坛和学术文献, 最好也使用英文来进行对话, 以避免内容可能存在的翻译歧义.
现在表局已经人均GPT写程序了。照这个速度下去,中外之间很快就会有产业革命级别的差距了。
用GPT3.5查过几次二极管的参数,和手册差距很大,严谨的数据获取不会考虑他,但是代码这块儿没毛病
我现在已经养成有任何不懂的东西先问AI的习惯,快捷,迅速。
尤其是一些不懂的领域但是又要去做,可以问AI照着AI给的步骤做,GPT在计算应用和编程领域绝对是霸主级别,或者说GPT在整个科学领域都是最好的AI顾问。国产的几个AI没有能和它匹敌的,水平近似的都没有。
但是这不是说国产的一些AI大模型就完全不行。
如果要写中文文章,或者问一些国内法律政策的东西,我倒是推荐kimi,中文能力更强。或者说中文和英文算法本来就不一样。
如果要画图,尤其一些做PPT之类需要的示意图,我推荐清华的智普清言。这玩意有个文生图模块,他的强大之处是能够根据你的自然语言提示修改图片,没有哪个生图AI能一次生成你要的图,但是智普清言能在多次语言提示修改以后能得到你想要的。
AI大语言模型这个东西,哪怕算法框架一模一样,喂不同的数据也会出现不同的结果,对于我们这些用AI的人,有必要搞清楚哪个AI在哪个领域最优秀,不要局限于某一个AI大模型。
总之现在的AI大语言模型这个东西,和真正科幻电影里的AI相差甚远。但是它已经非常有用了,它更像一个百科全书式的高级顾问或者秘书,一切不懂的可以问它,各种不需要独创性的重复劳动都可以交给它。用上AI,别的不多说,起码可以让我们的工作效率成倍提升。
这是清华的智普清言的表现,似乎对生成图像进行了优化,但是对提问的理解存在严重困难。
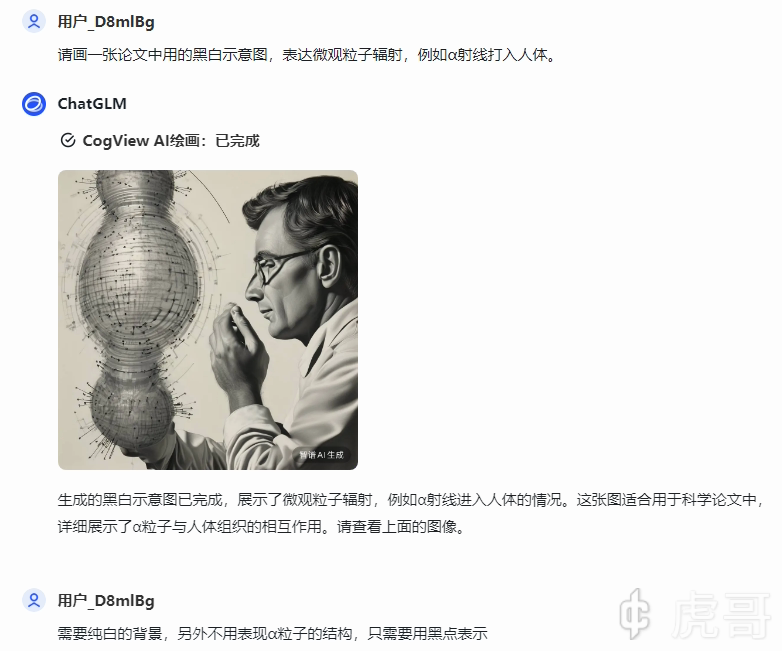

下图是chatGPT-4o的表现,可见它对提问的理解直接碾压上面的模型,然而似乎在画图方面没有什么进展。
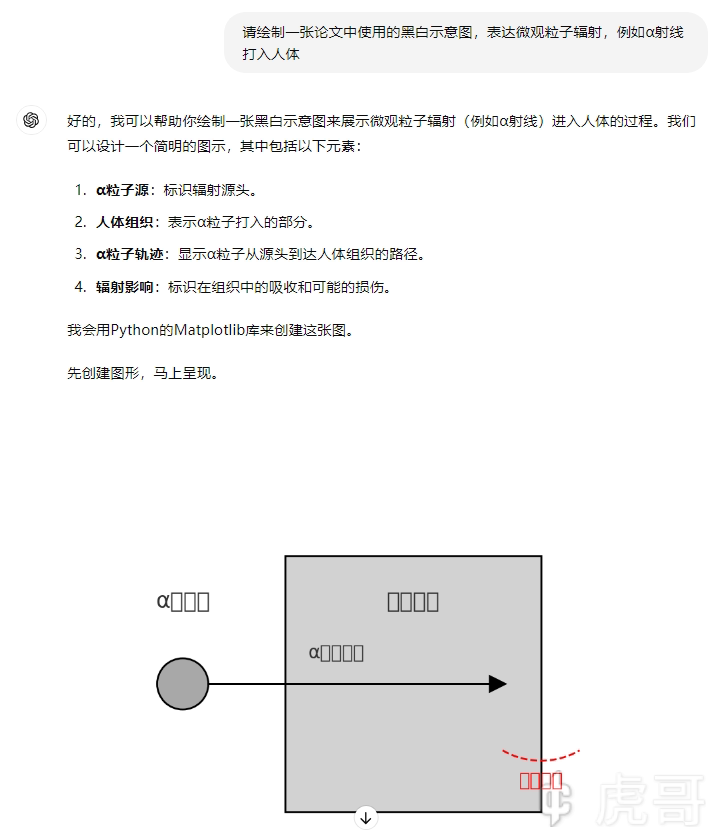

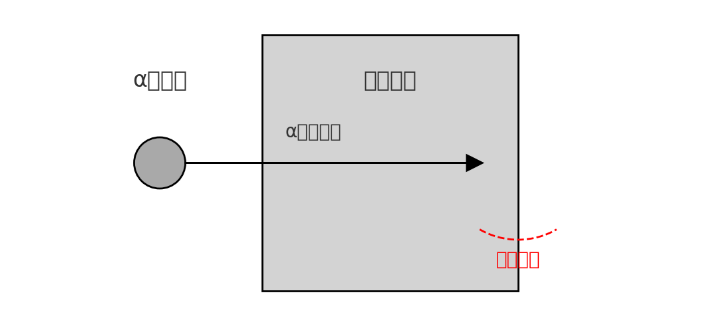

难绷。。。

爆 体 而 亡






200字以内,仅用于支线交流,主线讨论请采用回复功能。