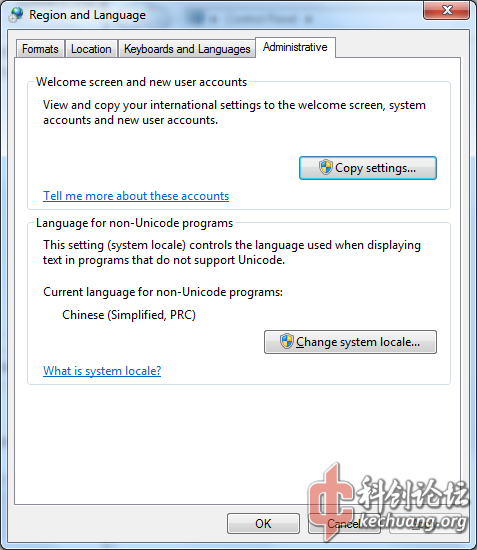
本人喜欢使用英文系统,为了避免老软件乱码以及不能输入中文的问题,一般需要将系统区域设置中的“非Unicode程序的语言”设为简体中文,如图所示:
![0.png]()
正确设置“非Unicode程序的语言”以后,基本上所有的中文程序都能正常运行了。
正因为如此,本人经常向本论坛、远景论坛、贴吧等的其他网友推荐英文版Windows,但是有些网友反映,有一小部分程序即使更改了也不行,这是怎么回事呢?
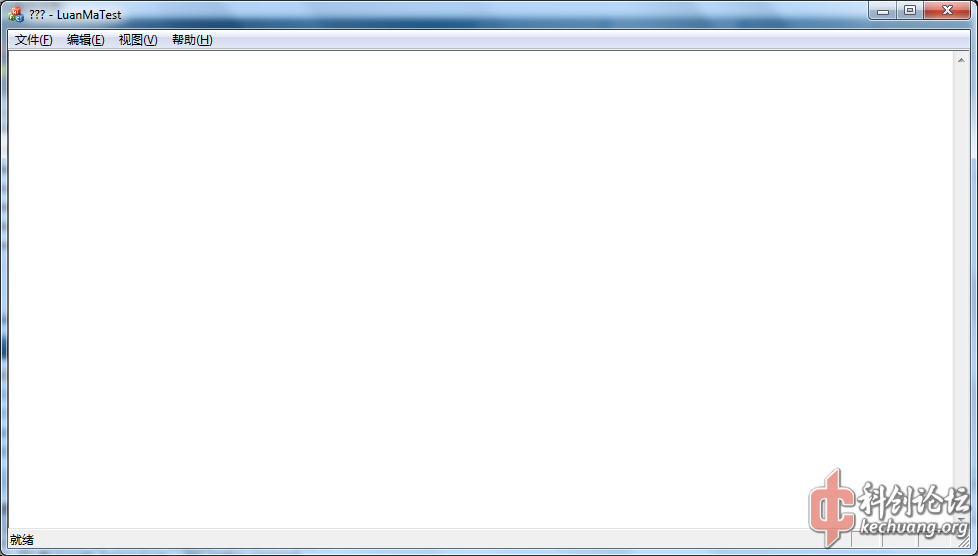
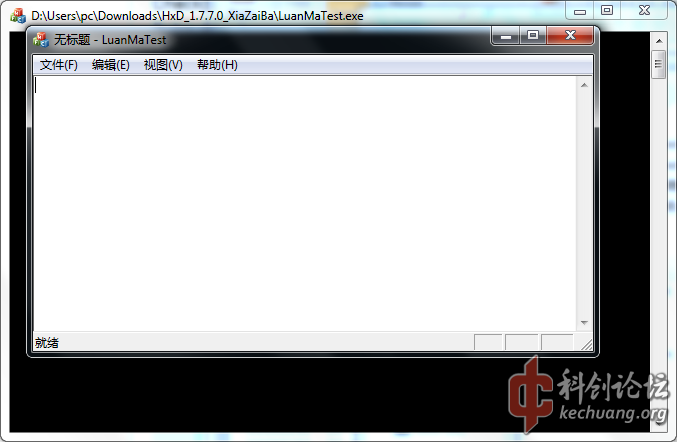
由于这是一种非常罕见的乱码,很长时间没有找到答案,直到我在使用VC++2008带的MFC时,发现它重现了这种乱码:
![1.png]()
这种乱码是怎么造成的呢?我发现,乱码的地方都是用CStringA::LoadStringA从资源段字符串表加载的。于是,我在这个函数下了函数断点。发现LoadStringA有多个重载,其中一个重载如下:
<code class="language-cpp"> _Check_return_ BOOL LoadString( _In_ HINSTANCE hInstance, _In_ UINT nID )
{
const ATLSTRINGRESOURCEIMAGE* pImage = AtlGetStringResourceImage( hInstance, nID );
if( pImage == NULL )
{
return( FALSE );
}
int nLength = StringTraits::GetBaseTypeLength( pImage->achString, pImage->nLength );
PXSTR pszBuffer = GetBuffer( nLength );
StringTraits::ConvertToBaseType( pszBuffer, nLength, pImage->achString, pImage->nLength );
ReleaseBufferSetLength( nLength );
return( TRUE );
}
</code>
发现它是由资源段直接读取Unicode字符串,再由ConvertToBaseType转换到ANSI字符串的,右击ConvertToBaseType转到定义,得到内容如下:
<code class="language-cpp"> static void ConvertToBaseType(_Out_cap_(nDestLength) _CharType* pszDest, _In_ int nDestLength,
_In_count_(nSrcLength) const wchar_t* pszSrc, _In_ int nSrcLength = -1) throw()
{
// nLen is in XCHARs
::WideCharToMultiByte(_AtlGetConversionACP(), 0, pszSrc, nSrcLength, pszDest, nDestLength, NULL, NULL);
}
</code>
ConvertToBaseType就是包装了WideCharToMultiByte函数而已,其中_AtlGetConversionACP函数决定了转换的代码页,右击它继续查找定义,得到:
<code class="language-cpp">inline UINT WINAPI _AtlGetConversionACP() throw()
{
#ifdef _CONVERSION_DONT_USE_THREAD_LOCALE
return CP_ACP;
#else
return CP_THREAD_ACP;
#endif
}
</code>
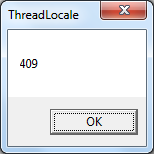
会不会是CP_THREAD_ACP的问题呢?我查了一下,它跟随ThreadLocale而变化。我尝试在MFC初始化之前插入一个GetThreadLocale调用:
<code class="language-cpp">// 唯一的一个 CLuanMaTest2App 对象
// 在theApp对象初始化前插入如下代码
class BeforeApp {
public:
BeforeApp()
{
CString str;
str.Format("%x", GetThreadLocale());
MessageBox(NULL, str, "ThreadLocale", MB_OK);
}
}beforeApp;
CLuanMaTest2App theApp;
</code>
![6.png]()
至此真相大白——409是英文的LocaleID,804是简体中文的LocaleID。
稍后奉上更深度的分析以及解决方案




200字以内,仅用于支线交流,主线讨论请采用回复功能。