
建议LZ直接开源,不然要获得那么多用户,有点难。
LZ需要什么类型的算力?最好先编写和debug完成再考虑算力问题。
为了执行效率,关键部分建议使用C/C++编写。
InfinitePi@Home
1.起因:
鄙人比较喜欢分布式计算,曾经参加过很多科学类和数学类的分布式计算,如GIMPS,F@H,WCG之类的
和F@H 3213群友聊天,突然想到Pi这个数学明珠竟然没有对其进行研究的分布式计算项目??
心血来潮,挖坑,走起。
查了好多资料,发现2004年有国人人利用JAVA2做过类似的项目,不过只是半成品,根本没有开始计算,觉得很可惜。
2.目标:
现阶段目标:利用Python+PHP两门语言,编写跨平台的、针对圆周率的分布式计算平台,并成功计算出圆周率小数点后一亿位,获得100位以上的用户量。到时候稳定下来了,决定开放源代码。
3.过程:
在肝了,在肝了,等我更新吧
这边鄙人刚刚注册科创论坛账号,也申请不到资金,只好自掏腰包先把服务器空位填上了,有意赞助硬件的也可以跟我P♂Y一波。。。
建议LZ直接开源,不然要获得那么多用户,有点难。
LZ需要什么类型的算力?最好先编写和debug完成再考虑算力问题。
为了执行效率,关键部分建议使用C/C++编写。
上午写了一下,用的是贝利-波尔温-普劳夫公式,Python CUDA计算,相当于并行了。
经过处理的数据:
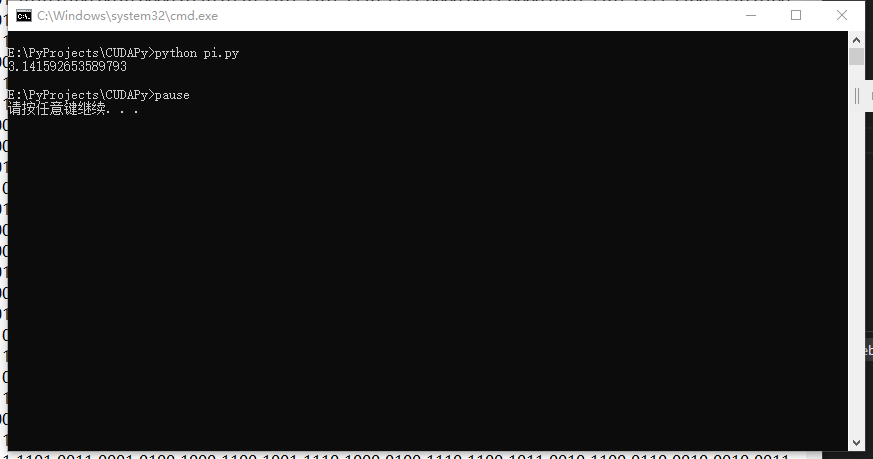
原始计算数据(一部分):

用自己的显卡算的,因为同时在运行其他使用CUDA的任务,速度就不测了
总结一些问题:
算法收敛慢且复杂度高,会越算越慢,效率远低于一般使用的算法
涉及到极大数据(16的n次方),有溢出问题,我用CUDA算出的结果就可能出现问题.还有高精度除法,编程难度高,执行效率低下.
所以这个方法似乎不适合大规模推广使用,分布式计算的成本甚至远高于直接算.
BBP算法已经有人写出来了一个https://github.com/tangtj/PI-Share,如果想参加就到https://pi.tangtj.cn/就可以了
看LZ好久不来回复,好久不上线,似乎也没什么诚意.
建议LZ直接开源,不然要获得那么多用户,有点难。LZ需要什么类型的算力?最好先编写和debug完成再...
感谢大佬回复!我是在校学生,住校的,所以到现在才回复!非常抱歉!
代码在写,没想到大佬已经把CUDA版本都写出来了,我的确是打算写出了可靠的代码后开源的。
大佬提出来的问题我也考虑到了,暂时也想不出来什么解决方法,而且也只有BBP算法能实现分布式计算,没法选用其他公式实现。
还有很多问题要考虑,我还是要以学业为重!
贴一下我写的程序...
Pythonimport multiprocessing
import time
def calc(cpu_number, cpu_total, result, total):
sumlimit = 1000
for n in range(cpu_number, total, cpu_total):
s1 = 0
s2 = 0
sum = 0
for k in range(0, n):
s1 += (pow(16, n-k) % (k * 8 + 1)) / (k * 8 + 1)
for k in range(n+1, sumlimit):
s2 += (pow(16, n-k)) / (k * 8 + 1)
sum += (s1 + s2) * 4
s1 = 0
s2 = 0
for k in range(0, n):
s1 += (pow(16, n-k) % (k * 8 + 4)) / (k * 8 + 4)
for k in range(n+1, sumlimit):
s2 += (pow(16, n-k)) / (k * 8 + 4)
sum -= (s1 + s2) * 2
s1 = 0
s2 = 0
for k in range(0, n):
s1 += (pow(16, n-k) % (k * 8 + 5)) / (k * 8 + 5)
for k in range(n+1, sumlimit):
s2 += (pow(16, n-k)) / (k * 8 + 5)
sum -= (s1 + s2)
s1 = 0
s2 = 0
for k in range(0, n):
s1 += (pow(16, n-k) % (k * 8 + 6)) / (k * 8 + 6)
for k in range(n+1, sumlimit):
s2 += (pow(16, n-k)) / (k * 8 + 6)
sum -= (s1 + s2)
ret = (sum % 1) * 16
if ret < 0:
ret += 16
result[n] = int(ret)
def main():
print('Using CPU')
startt = time.time()
grid = 4
block = 1024
total = grid * block
cpu_n = multiprocessing.cpu_count()
cpu_result = multiprocessing.Array('d', total)
process = []
for i in range(0, cpu_n):
print('Starting CPU ' + str(i))
p = multiprocessing.Process(target=calc, args=(i, cpu_n, cpu_result, total))
process.append(p)
p.start()
for i in process:
i.join()
f = open('pi_bin_CPU.txt', 'w')
for i in range(0, total):
f.write((bin(int(cpu_result[i]))).replace('0b','').zfill(4) + ' ')
f.close()
final = 3.140625
for i in range(2, total):
try:
final = final + cpu_result[i] / pow(16, i+1)
except:
break
print(final)
print('Time elapsed:' + str(time.time() - startt))
if __name__ == "__main__":
main()自学了python一两天,程序写不好见谅
我用Mathematica自带的圆周率函数计算一亿位圆周率,在单线程(3700x@4.2GHz)下,耗时64秒,占用内存150MB。。。


200字以内,仅用于支线交流,主线讨论请采用回复功能。