FCN和R-FCN论文指出,可以直接用全卷积网络(FCN, Fully-Convolutional Network)代替传统的conv-fc架构,这样便可以适应任意尺寸的输入,并且保留了输入图像中所包含的物体位置信息,可以直接根据卷积结果生成heat map和bounding box,省去了耗时的regression步骤。
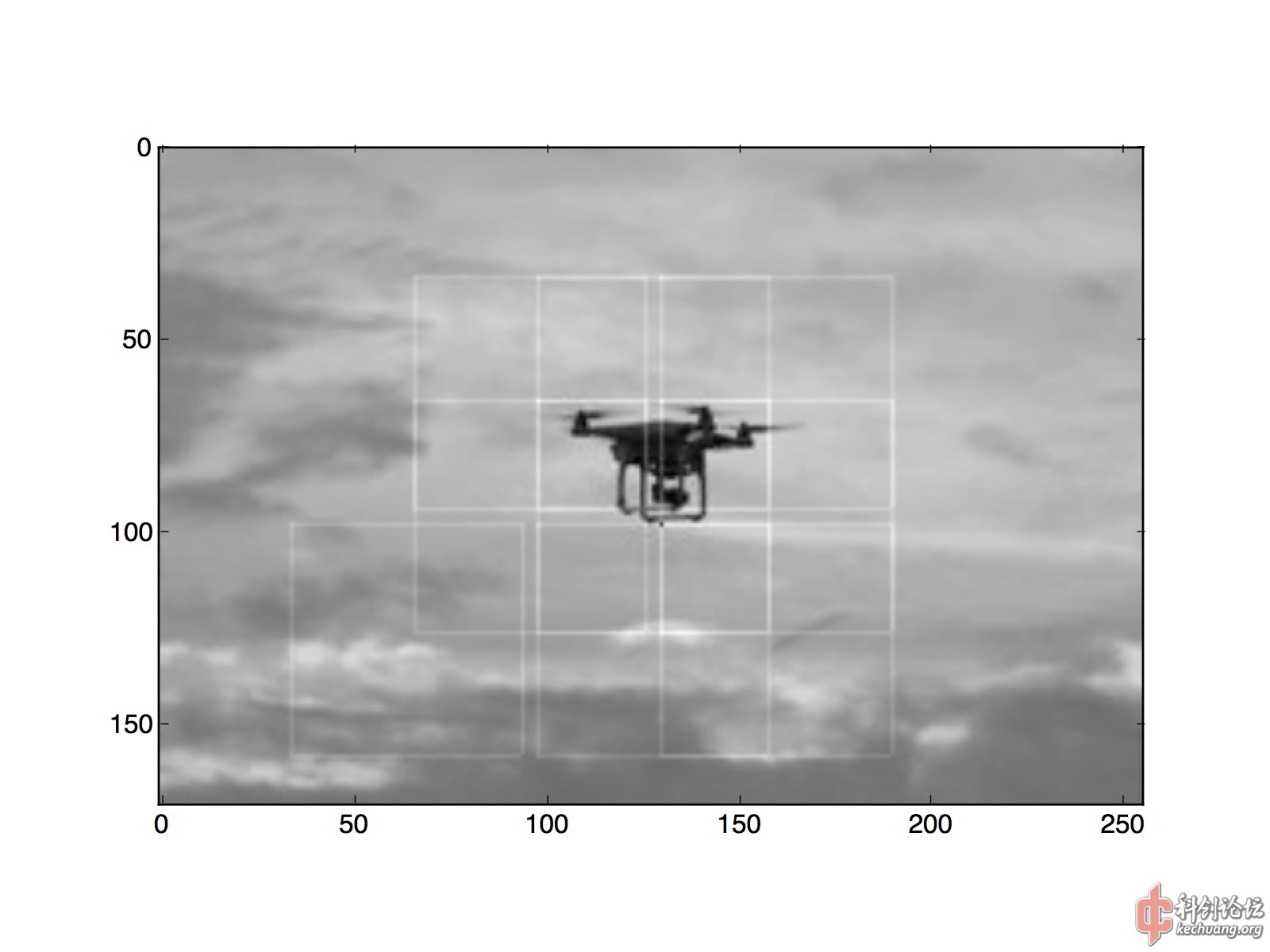
受到以上论文启发,我也修改了网络架构和训练方法。这是我目前正在训练的架构,左边是输入图像,右边是输出heat map。
![arch.png]()
这个架构有4个卷积层,其中conv1和conv2的作用是feature卷积,conv3和conv4则是代替传统架构中fc层的作用(!)。
因为使用了3x3和4x4两次pooling,最终输出的3x3heat map,覆盖的大概是原图中心36x36的范围。所以对于每个训练样本,我生成了一张36x36的heat map,将目标所在位置设为1.0,背景设为0.0 ,然后将这张map通过双线性插值,缩小到3x3,作为训练的ground truth。而训练样本中四轴飞行器的几何中心,也都落在图片中央36x36范围内。
那么,要怎么设计loss function呢?我们提供的ground truth取值范围在(0,1);而ReLU网络输出的取值范围是(0,+inf)。所以不能用mean squared error。因为架构特殊,Keras也没有提供我需要的误差函数,只好自己拼凑一个了:
<code class="language-python">def my_fancy_loss(y_true, y_pred):
# y_true within (0,1
# y_pred within (0,+inf
yt = tf.reshape(y_true,[-1,9]) # flatten
yp = K.softmax(tf.reshape(y_pred,[-1,9])) # flatten, then softmax
return 1.0 - K.mean(yp*yt, axis=-1)
</code>
代码中K是Keras后端,是tf的一层wrapper。因为Keras没有wrap tf.reshape函数,所以我直接混用了tf。
首先把3x3的预测值y_pred和3x3的ground truthy_true都展平成9维矢量,然后对预测值进行softmax,以将其取值范围压缩到(0,1)。然后将两个矢量逐项相乘,最后取平均,再取反。所以如果要降低误差,就要令逐项相乘的和尽量大。因为前面有softmax的存在,要让逐项相乘的和尽量大,预测值的最大值点就必须和ground truth的最大值点的位置接近,尽管最大值的绝对值可以不同。
为了本次训练,我从网上找了更多的无人机素材,生成了5000张64x64训练样例。考虑到每个人训练目的不同,这次我就不直接发生成好的dataset了,直接发透明的png素材。
 drones_resized.zip
143.25KB
ZIP
47次下载
drones_resized.zip
143.25KB
ZIP
47次下载





































200字以内,仅用于支线交流,主线讨论请采用回复功能。