加载中
加载中
表情图片
评为精选
鼓励
加载中...
文件下载
加载中...
如果你认真地读完了我上面写的帖子,我目前最新的总结是:classifier可以当detector用,但这不是最优方案。
对网络结构进行一些调整之后,我用1000个epoch、100/batch 把这个数据集跑到了0.9的准确率(期间验证了一点,SGDR确实是可以加速收敛的),考虑到数据集中存在的大量bug(比如全黑背景+全黑的无人机),这个准确率已经很棒了。
但是也遇到一些问题。数据集中用来生成背景的素材图,干扰主要是建筑物,从conv1的feature来看,网络已经学会了怎么从建筑物外墙棋盘般的背景中区分出无人机:

问题是这样效率比较低,比如我要丰富dataset,引入更多类型的背景,那么conv1的feature可能就不够用了,而加大conv1的后果就是……慢。尤其是,人眼在跟踪飞行器的时候,是处于一个在线学习的状态,即便是以前没有见过的无人机,看到在飞之后,就可以学习其外观并保持跟踪;即便是以前没有见过的背景,也应该可以实时适应,在视觉上能够积极地将无人机与背景进行区分(利用相对运动信息)。现在把feature全都做成死的、全都依赖训练数据,在实际环境中工作起来和人脑性能会差很远。所以要设计一个robust的tracker,很可能需要 cnn + lstm + very large real-world dataset,并按照抽象层次进行分阶段训练(从静态图片逐渐过渡到动态、从二维图像过渡到三维场景分析,而不是直接end-to-end)。将来会考虑用blender或者OSG生成这样的dataset。但在这之前,还是先认真刷论文吧。
下图:经过训练的binary classifier,可以通过sliding window的笨方法,在图中大致标记出无人机的所在。cnn输入窗口的宽度是64,因此我每32个像素predict一次,保证窗口之间的重叠,而且比逐个像素slide要快1000倍。图中每个命中的64x64窗口,用一个56x56矩形进行了标记。

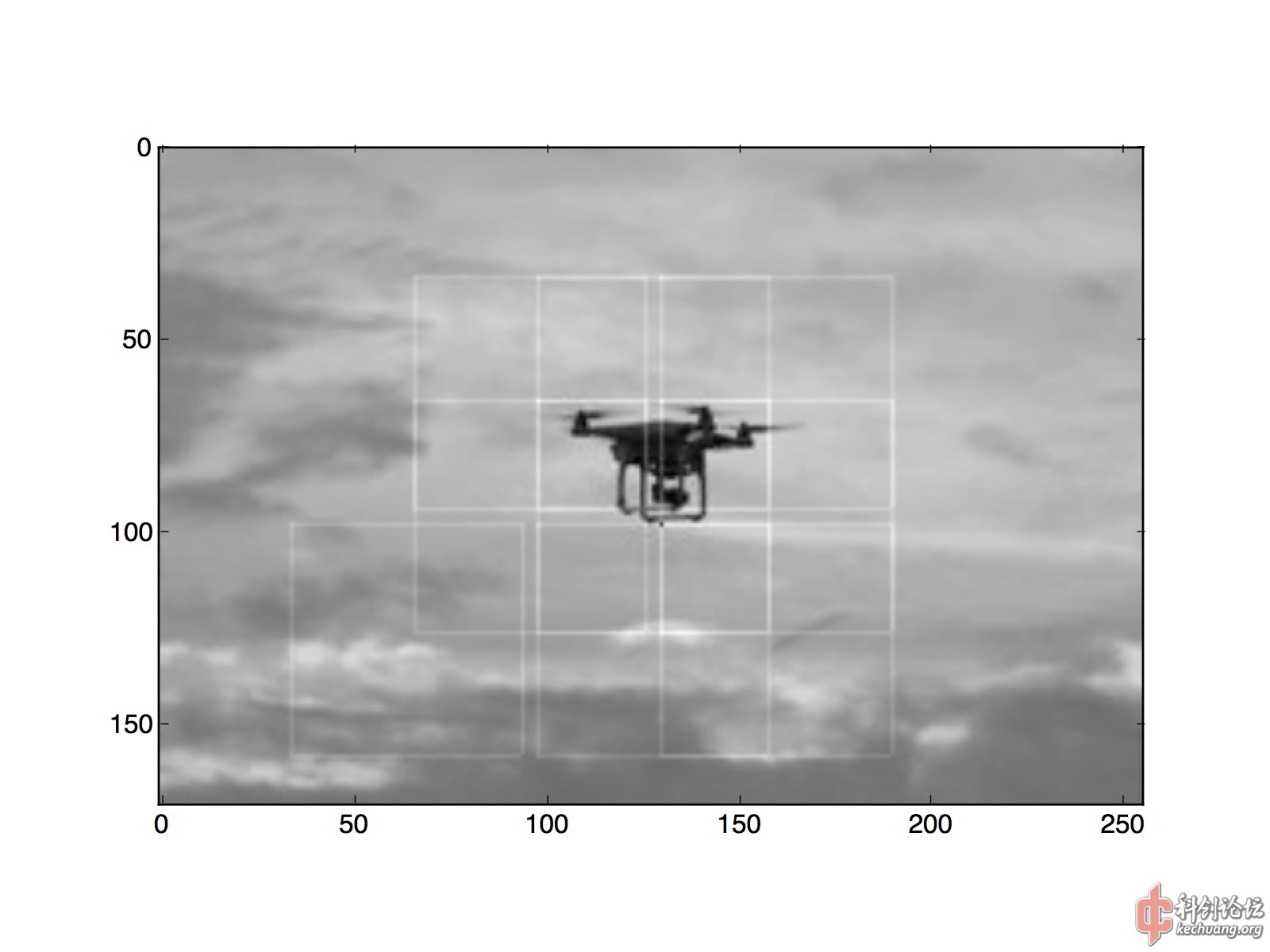
(请注意:每个小方格是32x32,predict window是64x64,每滑动32像素predict一次。框线是56x56.)
这其实是这两年ILSVRC做bounding box的主要方法:首先训练一个分类器网络(经过这3年的磨练,大家已经都学会了),然后用滑动窗口方法对图像应用这个分类器(然后对输出还要加一点SVM之类的魔法),以确定object在图中的位置。它们(比如R-CNN及其变种)的特点就是blackbox,naive,simple code,very slow。为了提速,大家提出了很多修修补补又三年的方法,不过始终都显得……不太美观,经常是一堆tricks然后结尾必提我们用多少个百分点的误差换了多少倍的速度……
结果就生产了一大堆大家都很清楚两年之后一定会变成废纸的文章,有点像当年手机厂商张口闭口都是跑分的情况。R-CNN minus R https://arxiv.org/abs/1506.06981 特别阐述了这一点。值得一提的是,他说:

对RPN的态度是Removing。
He Kaiming同学也一连发了几篇文章,表达对R-CNN(及其变体)效果的赞赏以及方法的不敢恭维,在此就不列出了。刚刚读了他的 R-FCN: Object Detection via Region-based Fully Convolutional Networks https://arxiv.org/abs/1605.06409 ,其中提到:

意思就是说,我们做图像分类的那个架构,是希望它对位移不敏感,所以越深、对位移越不敏感的卷积网络效果就越好。而做检测刚好相反,我们需要的结果恰好是对位移敏感的,所以用分类的那个架构来对付检测,就像用扫把洗碗,降低了比赛的观赏性质,对围观群众造成了brain damage。
一个美观优雅高速高效的detector究竟要怎么实现、怎么训练;作为最终产品的tracker要怎么利用detector的训练成果;这些都是接下来需要我去阅读思考的问题。
总结:Zhu Songchun说过,ML解决的仅仅是CV中的实现部分,如果不能确定到底要解决的是什么问题,再快的显卡也不管用。




