


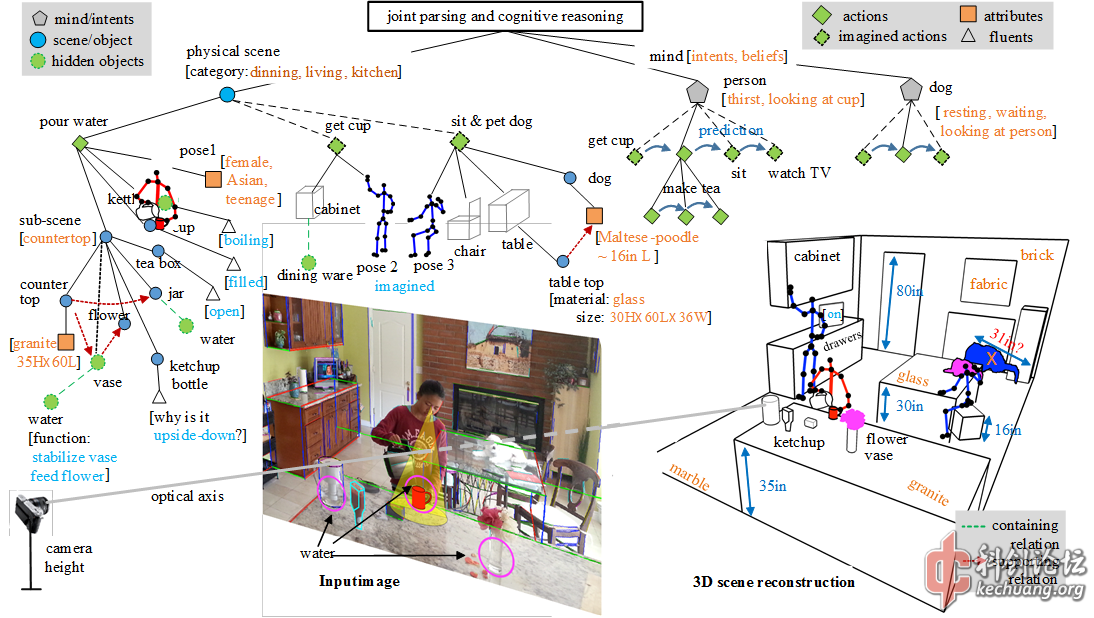
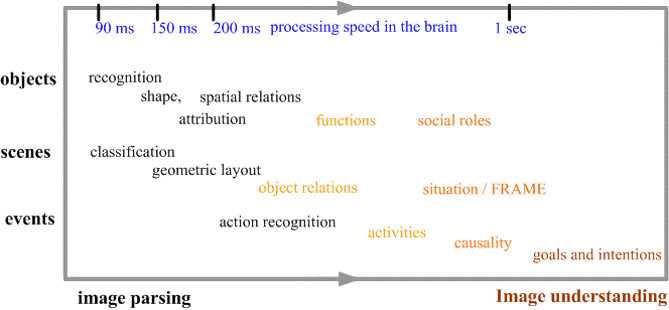
2. Is vision a classification problem solvable by machine learning? (2011)
Some students asked me whether vision is just an application area of machine learning (which currently means training Boosting or SVM classifiers with large number of examples) as it appears to them. If so, what left for vision researchers is just to design good features. Such question is a real insult to vision and reflects the misleading research trend that poses vision as simple as a classification problem. This is no longer surprising to me, as the young generation not only never heard of Ulf Grenander (the father of pattern theory), but now didn't know who David Marr (father of computational vision) was.
By analogy, machine learning, with its popular meaning, is very much like the method practiced by Chinese herbal clinics over the past three thousand years. Ancient people, who had little knowledge of modern medicine, tried on 100s of materials (roots, seeds, shells, worms, insects, etc) just like machine learning people test on various features. These ingredients are mixed with weights and boiled to black and bitter soup as drugs --- a regression process. It is believed that such soup can cure all illness including cancer, SARS and HmNn flu, without having to understand either the biologic functions and causes of the illnesses or the mechanism of the drugs. All you need is to find the right ingredients and mix them in the right proportion (weights). In theory, actually you can prove that this is true (essentially, modern medicine mixes some sort of ingredients as well), just like machine learning methods are guaranteed to solve all problems if they have enough features and examples, according to statistics theory! But the question is: with the space of ingredients so large, how do we find the right ingredients effectively (with realistic number of examples for training as well as number of patients for testing)? For vision, we got to study the complex structures of the images, the rich spaces and their compositions, and the variety of models and representations.

Comic: the analogy between Chinese herbal clinic and machine learning (by a painter Kun Deng and me drawn in 2008).


200字以内,仅用于支线交流,主线讨论请采用回复功能。