

打开Wolframalpha网站,然后搜搜就行了 注:国外网站,速度可能较慢。
80225
%7B%22isLastPage%22%3Atrue%2C%22notes%22%3A%5B%5D%2C%22pid%22%3A%22821169%22%2C%22tid%22%3A%2280225%22%2C%22mainForumsId%22%3A%5B%22134%22%5D%2C%22categoriesId%22%3A%5B%22438%22%5D%2C%22tcId%22%3A%5B%5D%7D
%7B%22isEditMode%22%3Afalse%7D
求是第几个质数的简易算法
昨天晚上看电影一不小心看到快4点,又一不小心打开科创,发现改版了,发现自己发帖要考试,还好过了,其中有一题,104667是第几个质数(不一定是这个数,记不太清了),我是用python编程求的
<code>def getPrime(n):
for i in range(2,n):
if n%i == 0:
return False
return True
def primePosition(x):
count = 0
if getPrime(x):
for i in range(2, x):
if getPrime(i):
count += 1
return count + 1
return count
</code>
结果是:9991

上面的函数不是很严谨,比如非法输入什么的都没处理。。。 差点忘了,话说python性能真不咋地,上面这题i5笔记本算了一分二十多秒。。。
[修改于 8年6个月前 - 2016/06/08 18:57:43]

引用 2480467935 : 打开Wolframalpha网站,然后搜搜就行了 注:国外网站,速度可能较慢。
多谢提供的网站,果然够慢。验证了下,答案正确

引用
加载评论中,请稍候...
200字以内,仅用于支线交流,主线讨论请采用回复功能。
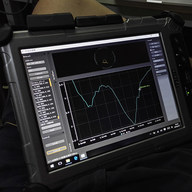



PrimePi[104677]
耗时不到2ms。。。

引用
加载评论中,请稍候...
200字以内,仅用于支线交流,主线讨论请采用回复功能。

VC++2015u2表示用楼主的算法在10秒以内出结果。。。
引用
加载评论中,请稍候...
200字以内,仅用于支线交流,主线讨论请采用回复功能。

首先不敢苟同楼主对 Python 性能的评价,按楼主的标准,汇编才是最好的语言。
其次看到楼上不少人以换语言和 IDE跑同一个O(n2)算法而得到的运算时间优化来满足优越感,表示无法理解其中乐趣。
对于质数筛选,已经有很多前人做了很多算法效率上的优化,这里话不多说,给出链接 Sieve of Eratosthenes , Sieve of Atkin,talk is cheap.
这里用XXXXXX作为统一平台,消去了IDE环境和硬件配置的影响,来比较楼主的O(n2)方法和一种以空间换时间的方法的运行效率:
1.简单算法:
<code>int whichPrime(int num){
if(num<4)return num-1; int numprime="2;" for(int i="4;i<=num;i++){" flag="1;" j="2;j*j<=i;j++){" if((i%j)="=0){" break; } numprime+="flag;" return numprime; < code></4)return></code>
测试结果 0.014957 S:

2.优化算法:
<code>int whichPrime(int num){
if(num<4)return num-1; vector<int> list (num-1,1);
for(int i=2;i*i<=num;i++){ if(list[i-2]){ for(int j="i*i;j<=num;j+=i){" list[j-2]="0;" } int numprime="0;" i="0;i<list.size();i++)" numprime+="list[i];" return numprime; < code></=num;i++){></4)return></code>
测试结果 0.001196 S:

引用
2
加载评论中,请稍候...
200字以内,仅用于支线交流,主线讨论请采用回复功能。
引用 琪露诺 : 首先不敢苟同楼主对 Python 性能的评价,按楼主的标准,汇编才是最好的语言。
其次看到楼上不少人以换语言和 IDE跑同一个O(n2)算法而得到的运算时间优化来满足优越感,表……
无形装逼,最为致命 【这很清真】
引用
加载评论中,请稍候...
200字以内,仅用于支线交流,主线讨论请采用回复功能。
引用 琪露诺 : 首先不敢苟同楼主对 Python 性能的评价,按楼主的标准,汇编才是最好的语言。
其次看到楼上不少人以换语言和 IDE跑同一个O(n2)算法而得到的运算时间优化来满足优越感,表……
在VC2015u2上跑,
Release编译下,第一个是0.015089,第二个是0.000556,快了30倍
Debug编译下,第一个是0.024269,第二个是0.294831,慢了10倍以上
说明vector在Debug编译下由于要进行各种调试检查,资源和时间消耗非常大。
一个超(zuo)快(bi)的算法:
<code class="language-c">// 提前准备一个prime table // 做binary search </code>
引用
加载评论中,请稍候...
200字以内,仅用于支线交流,主线讨论请采用回复功能。
引用 undefined : > 引用 琪露诺 : 首先不敢苟同楼主对 Python 性能的评价,按楼主的标准,汇编才是最好的语言。
其次看到楼上不少人以换语言和 IDE跑同一个O(n2)算法而得到……
回楼上,既然都用查表法了,为什么不更直接用 hash table 这种? O(1) 时间内就可以了。
引用
加载评论中,请稍候...
200字以内,仅用于支线交流,主线讨论请采用回复功能。
引用 undefined : > 引用 undefined : > 引用 琪露诺 : 首先不敢苟同楼主对 Python 性能的评价,按楼主的标准,汇编才是最好的语言。
其次看到楼上不少人以换语言和 IDE跑同一个……
哈哈。。。还是你厉害。。。内存够的话,不如直接列个索引表了。。。
引用
加载评论中,请稍候...
200字以内,仅用于支线交流,主线讨论请采用回复功能。

<code class="language-python">from math import sqrt
def getPrime(n):
if (n!=2) & (n&1==0) :
return False
for i in range(3,int(sqrt(n))+1,2):
if n%i == 0:
return False
return True
def primePosition(x):
count = 0
if x==2:
return 1
if (x>1) & getPrime(x):
for i in range(3, x,2):
if getPrime(i):
count += 1
return count + 2
return count
</code>
引用
加载评论中,请稍候...
200字以内,仅用于支线交流,主线讨论请采用回复功能。
楼主的算法用C#跑的结果:
Debug x64版本,用了10.2742583秒
Release x64版本,用了7.5063185秒
引用
加载评论中,请稍候...
200字以内,仅用于支线交流,主线讨论请采用回复功能。


线性筛可破。O(N)
主要思想是,每个数只被他最小的质因数筛去。
从小到大看,如果某个数是质数,那就把这个数乘以所有比他最小的质因数小于或等于的质数得到的数全都筛掉,并且标记最小质因数。
嗯我说的好像不太清楚,这个网上全都是吧
主要思想是,每个数只被他最小的质因数筛去。
从小到大看,如果某个数是质数,那就把这个数乘以所有比他最小的质因数小于或等于的质数得到的数全都筛掉,并且标记最小质因数。
嗯我说的好像不太清楚,这个网上全都是吧
引用
加载评论中,请稍候...
200字以内,仅用于支线交流,主线讨论请采用回复功能。

……只会c的弱鸡,还停留在函数调用,,,拿循环编出来的。比不过大佬们……
引用
加载评论中,请稍候...
200字以内,仅用于支线交流,主线讨论请采用回复功能。

前面一位搞程序的说了,不是最优的算法,的确他算法和程序方面很大神了,但是我觉得炫耀成分多于想要帮人解决问题。
抛个数学为主的方法给你们,传送门:XXXXXXXXXXXXXXXXXXXXXXX/view/XXXXXXXXXXXXXXXXXXXXXXXXXXXml
这个复杂度怎么样?我不太会算,O(n)?
引用
加载评论中,请稍候...
200字以内,仅用于支线交流,主线讨论请采用回复功能。

楼上抛出的问题很有意思啊。
设函数ϕ(x) 等于不大于x的全体质数个数,则时间复杂度可以表示为O(ϕ(⌊√N⌋)) 。
因为算法的关键路径:
用小于K的所有质数去除N
(其中K=⌈√N⌉ )
可通过一个循环体来实现,循环次数 T=ϕ(K−1) 。
自然地,时间复杂度就为O(ϕ(⌈√N⌉−1)) = O(ϕ(⌊√N⌋)) 。
PS: 这里还涉及一个数据循环依赖的问题,我们姑且认为程序事先知道小于K的所有质数。
那么问题来了,ϕ(x) 是个什么样的函数呢?似乎黎曼等学者曾经研究过相关问题,过于深奥,这就愁坏了我个非数学专业的。
不过,单看上界ϕ(x)≤x 必然成立,有O(ϕ(x))=O(x) ,于是得到时间复杂度为:
O(√N) 。
虽然在全体正整数集上不清楚ϕ(x),但在有限范围内还是可以画出图像,观察得到N<=1e6总体呈线性增长,但斜率小于1。也就是说,这个算法可以作为同样具有O(√N) 复杂度的暴力解法的系数优化版本。

但是这个算法实用嘛?前面说过,存在数据的循环依赖,不利于计算机去算。如果打表的话,优势似乎就没了。。。
引用
加载评论中,请稍候...
200字以内,仅用于支线交流,主线讨论请采用回复功能。
楼上抛出的问题很有意思啊。设函数ϕ(x) 等于不大于x的全体质数个数,则时间复杂度可以表示为O(ϕ(...
如果不查表的话,
用这种方法判断质数成功后,做标记,也是要比一个个判断效率高很多吧。
PS:用空间换时间后,这个算法效率还会更高。可惜我没楼上这么强的技术水平。只是一个想法
引用
加载评论中,请稍候...
200字以内,仅用于支线交流,主线讨论请采用回复功能。
如果不查表的话,用这种方法判断质数成功后,做标记,也是要比一个个判断效率高很多吧。PS:用空间换时间...
嗯嗯。但是做标记太笼统了。顺着链接的思路,您想说的应该是动态规划:从2开始,用这种方法由小到大逐个构建出素数表,但是每判断一个质数都要搜索前面的素数表(素数表用标记实现)。
其实换个方向就成了经典的埃氏素数筛:对于已经判断出是质数的数,不管它的前驱,而是标记后面已知不可能成为质数的数。这方法效率的确是高的,但是跟链接里面的算法还是有区别。
另外恳请管理员帮忙编辑一下,原文“楼上的抛出问题”改为“楼上抛出的问题”。
还有不是很懂为啥LaTex公式会渲染成这样。
引用
加载评论中,请稍候...
200字以内,仅用于支线交流,主线讨论请采用回复功能。