89585
%7B%22isLastPage%22%3Atrue%2C%22notes%22%3A%5B%5D%2C%22pid%22%3A%22925661%22%2C%22tid%22%3A%2289585%22%2C%22mainForumsId%22%3A%5B%2216%22%5D%2C%22categoriesId%22%3A%5B%22369%22%5D%2C%22tcId%22%3A%5B%5D%7D
%7B%22isEditMode%22%3Afalse%7D
关于KC761手机软件输出Csv文件横坐标为通道数的解决方案
中文摘要
咦?我好像发现了KC761手机app的一个bug,不过不妨让我们玩玩这个bug(bushi
关键词
KC761校正bugapp拟合
小白第一次写论坛没什么经验就当水一贴吧(划掉)
0.问题描述:
最近入了台KC761,虽说没赶上内测,但是现在这个价格依然还是很香很香。不过言归正传,当我用手机app导出Csv文件时却发现在其他能谱app中永远对不上的问题:
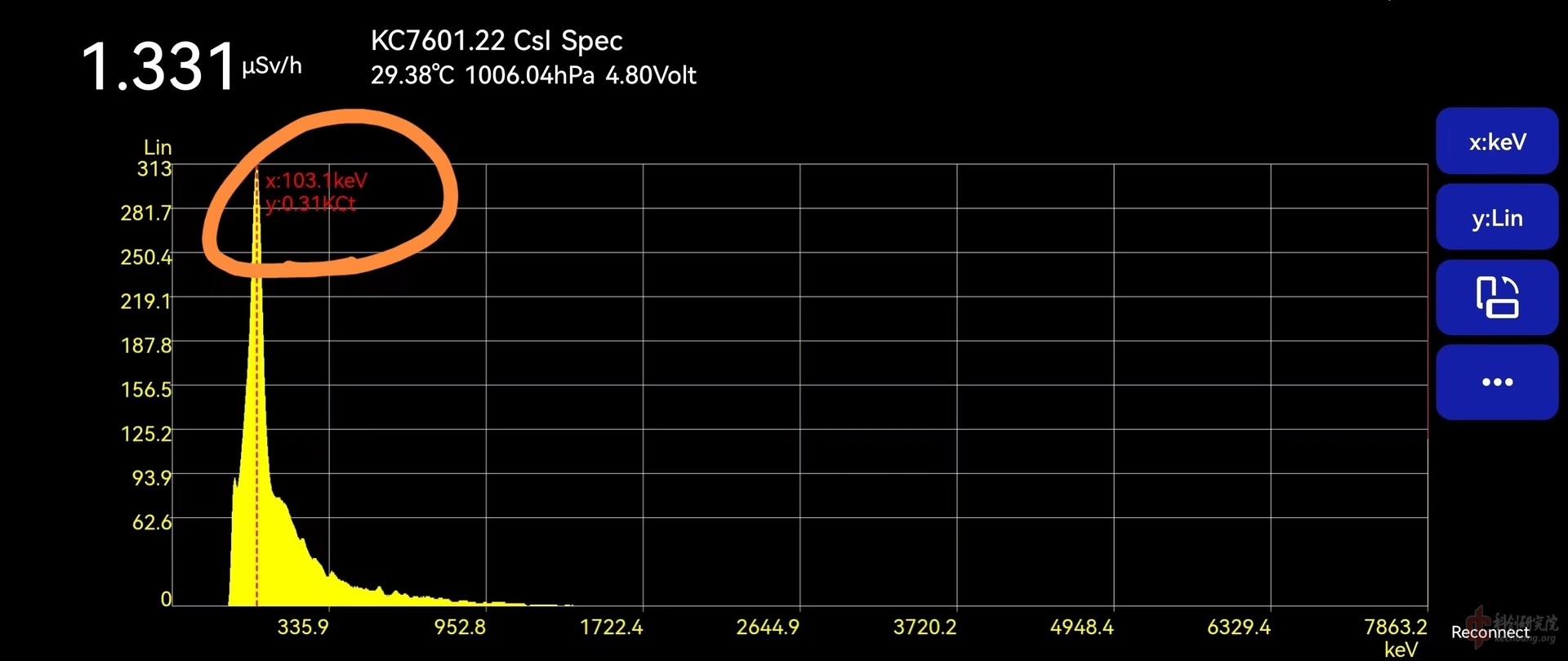

聪明的小伙伴可能一下就猜出了问题所在:

是的,app里面输出的Csv文件用的是(通道,计数)的格式,而在其他软件中却被误解析为(能量,计数)的格式。这造就了谱图的大量偏移。
到这里可能有人会说:你这直接让第三方软件校正一下不就好了?
但是事实上直接校准并非易事,原因有三:
没有校准源/谱图特征峰时是图谱是无法校正的。
事实上KC761的通道数和对应能量值并非线性关系(一会儿我们详细讨论),可能无法精确校正。
一个通道的范围对应了多个能量值,而软件把你的一个通道理解成了一个能量值,因此图谱曲线偏高,你还需要校准相对能量值。
1.解决过程
那还是让我们自己搞定它吧:)
首先我们得搞清楚KC761通道数和能量值的关系,好在app里面可以直接看到这些数值,那么我们简单统计一下:

哎呀,竟然不是直线,不过不慌,这个时候我们就要用到珍藏多年的fx-991CN了


函数:$Energy=1.166*10^-3Channel^2+1.5139hannel-128$
只能说,完美:)
不过,我们实际上要的是把Csv文件中的"假能量值"对应为"通道数",而上面的函数是反过来的,因此我们要求上面函数的反函数。
如果是高中我大概可以秒杀掉这道题,但很可惜现在已经是个合格的大学牲了,初等数学?dbq一点也不会捏。
于是只能开始从简单的二次函数试,然后慢慢找规律。跳过一些无脑操作,反正最后总结出来二次函数的反函数是:
$y=ax^2+bx+c (y>x) → x=(sqrt(4ay+b^2+4ac)-b)/2a$
嗯当然Energy-Channel函数也不例外,我们因此得以求出:
$Channel=(sqrt(4.664*10^-3Energy+2.88888521)-1.5139)/(2.332*10^-3)$

到此,数学部分大功告成,剩下的就要交给计算机了?
不过等等!
我们先看看Csv文件的格式:

只能说格式简单明了(敲代码应该会好敲很多),但是:
实际上通道数远小于能量值数个数,因此校正时能量值数目和通道数目肯定会出现很多多对一的情况,那么对应能量值的计数个数该如何写呢?
直接多个能量值全部用通道计数值?
当然不行,这样的话虽然图像趋势不变,但是你的总计数值平白无故直接翻倍,数据可靠性大大下降。
那如果我们把相同通道的能量值都除以共用该通道的个数呢?
听起来很合理并且总计数也不会有太大影响,但是事实真的如此吗?在低能区一个通道对应2或3个能量值(事实上非整数值,只是在统计时会是2或3个)。低能区的通道的计数变化趋势基本是连续的,但在你处理的时候却有的值采取通道计数除以二,有的值采取通道计数除以三,那么处理后的数据将会是参差不齐,失去了连续性,严重影响了图像。
最终我采取的方式是:将每一能量值对应的计数除以该值在Channel-Energy图像(简称C-E图了)相应位置的导数,可以理解成除以了一个该区域一个通道对应的能量值数的平均值。(求导过程略)
好的,我们求完导终于可以进入下一环节——码代码:
首先声明一下本人大学化学专业,几乎无计算机基础,只会一点Python就充一下数了。
import math
import os
import numpy as np
energy = np.arange(0.5, 4000.5, 1) #此处填写修改能量区间范围以及最终生成文件能量区间范围
channel = []
value = []
para = []
for eachEnergy in energy:
eachChannel = int((math.sqrt((4.664 / 1000) * eachEnergy + 2.88888521) - 1.5139) / (2.332 / 1000)) + 0.5
channel.append(eachChannel)
eachPara = math.sqrt((4.664 / 1000) * eachEnergy + 2.88888521)
para.append(eachPara)
path = r"YourDirectory\" #此处填写文件地址,相对绝对地址均可,以\结尾!
for eachfile in os.listdir(path):
filename = eachfile
if filename[-4:] == ".Csv":
with open(path + filename) as rawFile:
file = rawFile.read()
filename = filename[:-4]
for chs in channel:
idx = file.find(str(chs))
val = ""
while (file[idx] != ','):
idx += 1
idx += 1
while (file[idx] != '\n'):
val += file[idx]
idx += 1
value.append(int(val))
for i in range(len(energy) - 1):
value[i] = int(value[i] // para[i]) #此处会导致数值变低0-1Ct,但不会影响统计学意义
if not os.path.exists(path + filename[:-7] + '_corred' + '.Csv'):
with open(path + filename + '_corred' + '.Csv', 'w') as newFile:
newFile.write("Energy,data\n")
for i in range(len(energy) - 1):
newFile.write(str(energy[i]) + ',' + str(value[i]) + '\n')
os.remove(path + filename + '.Csv')
input("执行完毕,按任意键退出......")2.效果展示
嗯然后我们运行代码看看效果?

嗯效果显著嘿嘿,我们成功第把尖峰挪回了原来的位置
不过细心的小伙伴可能又发现了,你这处理完之后怎么total count还变少了呢?
对于这个问题我们回过头来仔细看看程序,找到标有“ #此处会导致数值变低0-1Ct,但不会影响统计学意义
”的那行。由于各个能量的count只能是整数,而我们通过通道能量值(原value[i]变量)除以C-E图的导数(para[i]变量)大概率得到的是小数,因此我选择了地板除,即除完直接扔掉小数部分。这样的话肯定会使total count减小,不过每个能量值最多被减去1计数,因此并不会影响图像统计学意义。
好的,我的第一篇论坛就水到这了,不过咱就说有没有一种可能,其实这个是个app的bug,改一下导出Csv输出的内容就行233
[修改于 1年2个月前 - 2023/09/28 00:45:04]
小蒜肝油
 进士 机友
进士 机友
作者最新文章