看到跟计算机有关的,本noip蒻驹必须顶一个(dog)
看不出有什么错误,可能是我不懂python和爬虫吧 。写得很好,通俗易懂,完整性和实用性在我近期看过的文章中是独一无二的。kc这种公益网站应该没什么禁忌吧,估计爬不到多少有商业价值的信息。
。写得很好,通俗易懂,完整性和实用性在我近期看过的文章中是独一无二的。kc这种公益网站应该没什么禁忌吧,估计爬不到多少有商业价值的信息。
kc币就不用了,好帖该有的样子,赞。
前言:想搞爬虫很久了,总因为各种事情耽搁,这几天浅学了爬虫应用,想找个网站练习练习,盯上了KC(哈哈)。我爬取了KC我目前有权限看到的文章的时间、文号、标题、简介并把这些信息导入了.txt和.xls并制作了词云图。(本人爬虫小白,刚学了几天,文章定有不少错误,欢迎各位提出)
分析网页:
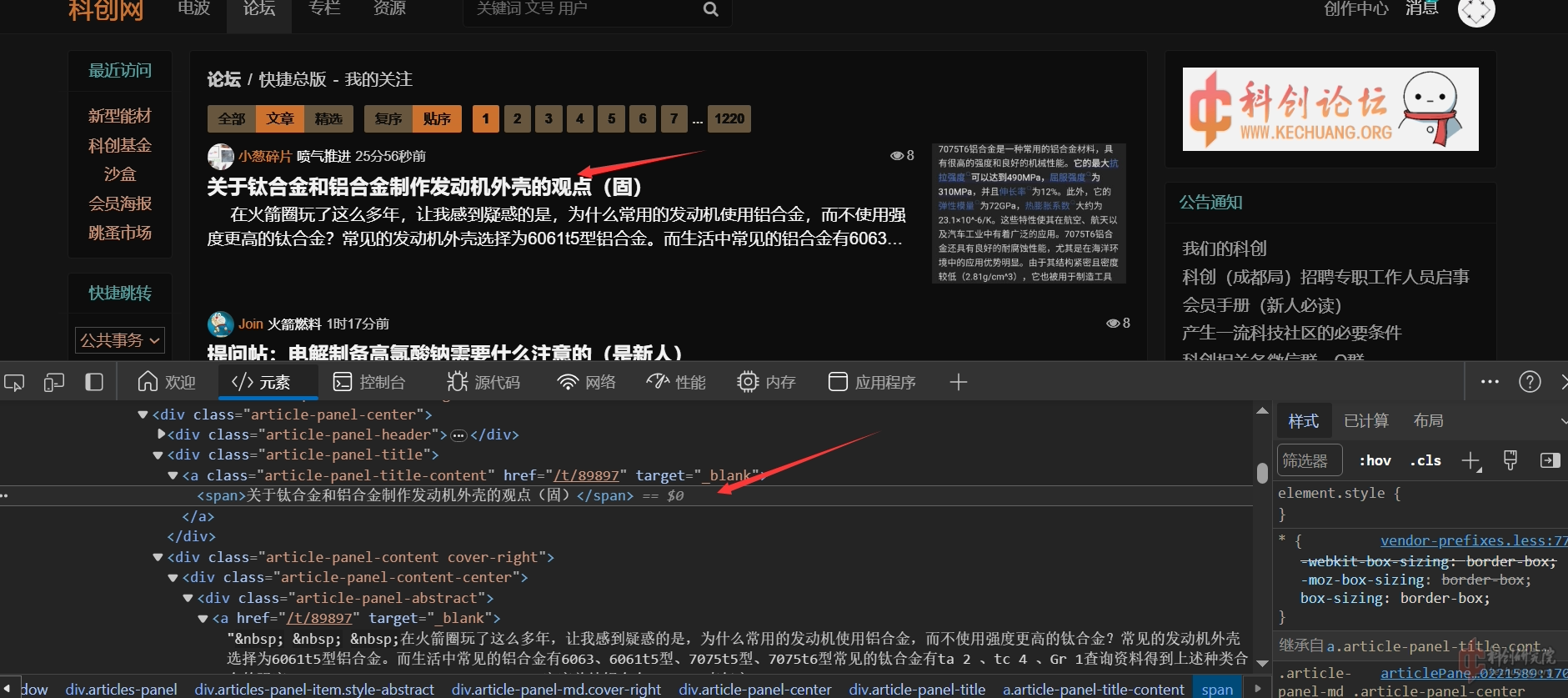
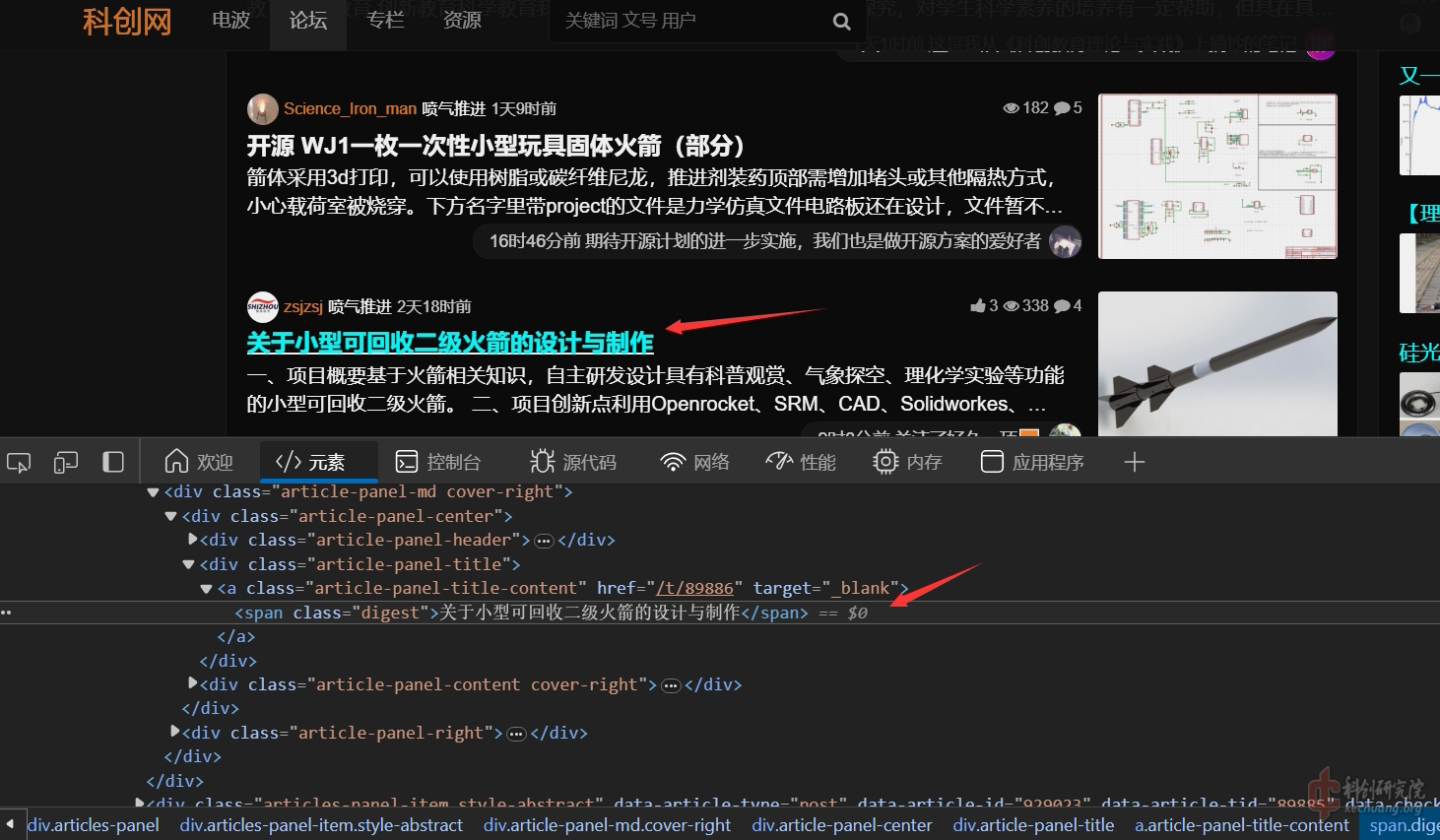
我们可以看到,精选文章和非精选文章的的标题存放的结构是不同的(我当时爬取的时候被这个地方卡了,导致有些标题没有匹配到)
获取标题我采用的正则表达式是:
find_name = re.compile(r'<div class="article-panel-title"><a class="article-panel-tit.*?<span.*?>([\s\S]*?)</span></a>')([\s\S]*?)代表了任意字符都能匹配,包括换行符,如果使用(.*?)不会匹配到换行符,导致部分标题匹配失败,也可以在式子里面插入.*?忽略掉不一样的信息,辅助定位。
我们还需要获取文章号和发表日期:
find_time = re.compile(r'data-time-type="fromNow" data-type="nkcTimestamp" title="(..........)')这里面的(..........)就是匹配.的数量个字符的意思,匹配除换行符(\n、\r)之外的任何单个字符,相等于 (^\n\r)。
获取简介和文号:
find_synopsis = re.compile(r'<div class="article-panel-abstract"><a href="/t/.*?" target="_blank">([\s\S]*?)</a></div>')
find_serial = re.compile(r'data-article-tid="(.*?)"')有些文章的简介会有奇奇怪怪的字符和分行<br>那些东西,所以也使用了([\s\S]*?)的方式获取
多线程:
接下来我们需要把网页爬下来,为了加快速度,使用多线程,开了10条线程爬取,没有使用线程锁,注意,别开太多线程,到时443Error就不好玩了:
thread_list = []
for i in range(0, 10):
thread = threading.Thread(target=down_task, args=[i])#这个args能传进去参数
thread.start()
thread_list.append(thread)
for t in thread_list:
t.join()Cookie获取
如果不带入Cookie爬取,因为权限问题,能阅读到的文章大概只有555页(2024.2.3)

进入开发者模式,点网络,刷新一下页面,点文档,翻下去能找到你自己的Cookie,复制粘贴便是了。
这个是请求头(但为什么不用带入User-Agent请求KC网的数据也不返回418报错?):
#请求头,可以带入cookis因为有些网站需要登录才能查看内容
headers = {
"Cookie":"userInfo=xxxxxxxxxxxxxxxxxxxxxxxxxxxxxxxx" #换成你自己的
# "User-Agent":"Mozilla/5.0 (Windows NT 10.0; Win64; x64) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/120.0.0.0 Safari/537.36 Edg/120.0.0.0"
}分开爬取的函数(爬虫主体):
def down_task(task_num):
global i_num
try:
for i in range(0, 1220, 10):#这个1220是因为我有权限阅读的文章刚好就是1220页(2024.2.3)
i_num = i
response = requests.get(f"https://www.kechuang.org/c/new?page={i+task_num}&t=thread&s=toc", headers = headers, timeout = 20)
time.sleep(0.5)
html = response.text
time.sleep(0.5)
# 接下来是逐一解析数据
bs = BeautifulSoup(html, 'html.parser')
# 使用标签 + 属性组合查找,查找标签块
f_list = bs.find_all('div', attrs={"class": "articles-panel-item style-abstract"})
# print(f_list)
for f in f_list:
data = []
# 将正则表达式提取的内容赋值给自定义变量
fine_time = set_film(find_time, str(f))
file_name = set_film(find_name, str(f))
fine_synopsis = set_film(find_synopsis, str(f))
fine_serial = set_film(find_serial, str(f))
# 将所有需要的数据保存到data列表
data.append(fine_time)
data.append(file_name)
data.append(fine_serial+' '+str(i+task_num))
data.append(fine_synopsis)
# 写入data(单条文章信息)列表,到总的 data_list(所有文章信息)列表
data_list.append(data)
print(data)
response.close()
except:#保存报错信息
file = open('C:/Users/lyl/Desktop/kechuang/original_file/error.txt', 'w', encoding='utf-8')
file.write('error' + " {} {}".format(i_num,task_num) + '\n')#知道哪条线程error了
file.close()
errorFile = open('log.txt', 'a')
traceback.print_exc()
errorFile.write(traceback.format_exc() + '\n')#报错信息写入日志文件
errorFile.close()获取解析数据延迟一下,爬太快有可能:
requests.exceptions.SSLError: HTTPSConnectionPool(host='www.kechuang.org', port=443): Max retries exceeded with url: /c/new?page=771&t=thread&s=toc (Caused by SSLError(SSLEOFError(8, 'EOF occurred in violation of protocol (_ssl.c:1002)')))这个也有可能出现:
requests.exceptions.ChunkedEncodingError: ('Connection broken: IncompleteRead(4090 bytes read, 4248 more expected)', IncompleteRead(4090 bytes read, 4248 more expected))这个报错查资料说主要原因可能还是请求速度过快,而且可能还有一个原因就是网络不好(可以尝试换一个好一点的网络)当页面还没完全解析就已经开始爬取了,所以一般爬取到的结果为空,也可能会只爬了一部分,没有完全读取完。
set_film()是检验用的,防止有些内容是空的写入列表就Error了,函数如下:
def set_film(file, content):
#这是防止有些内容是空的,就会报错,先判断是否非空
# 检查查找内容的长度,如果不为0,说明查找到内容,则将内容转换成字符串类型
if len(re.findall(file, content)) != 0:
film = str(re.findall(file, content)[0])
else:
film = "--空--"
return film保存到.txt,一条条写进去就是了:
def save_data_txt(datas, save_file):
# 打开文本选择写模式,并指定编码格式
file = open(save_file, 'w', encoding='utf-8')
# 不能直接写入list,所以通过遍历一条条写入
for data in datas:
for dat in data:
file.write(dat + '\n')
file.write('--next--' + '\n')
file.close()保存数据到excel文件中:
#设置格式
def set_font(bold, size, horz):
# 创建xlwt格式对象
style_font = xlwt.XFStyle()
# 设置字体是否为粗体
style_font.font.bold = bold
# 设置字体尺寸大小
style_font.font.height = size
# 字体是否居中
if horz:
# 设置字体水平居中
style_font.alignment.horz = 0x02
# 设置字体垂直居中
style_font.alignment.vert = 0x01
# 设置单元格自动换行
style_font.alignment.wrap = False
# 返回设置的字体样式
return style_font
# 保存数据到excel文件中
def save_data_excel(datas, save_path):
# 创建一个xlwt对象,使用utf-8编码格式
excel = xlwt.Workbook(encoding='utf-8')
# 创建一个工作表,命名为top250
sheet = excel.add_sheet('kechuang')
# 设置列的列宽
width_c = [256*15, 256*40, 256*10, 256*2560]
for i in range(0, 3):
sheet.col(i).width = width_c[i]
# 设置三种单元格样式 set_font(粗体,尺寸,居中)
style_font_title = set_font(True, 240, True)
style_font_content = set_font(False, 220, True)
style_font_content1 = set_font(False, 220, False)
# 表格各列的列名
titles = ['time', 'name', 'serial', 'synopsis']
index = 0
# 将标题写入excel
for title in titles:
# (单元格行序号,单元格列序号,单元格的内容,单元格样式)
sheet.write(0, index, title, style_font_title)
index += 1
# 将数据写入excel
index_r = 1
for data in datas:
index_c = 0
for item in data:
sheet.write(index_r, index_c, item, style_font_content1)
index_c += 1
index_r += 1
# 保存excel文件到指定路径
excel.save(save_path)处理数据,先把原始数据读入数组,再按照年份划分标题:
def read_data_in_list():#数据读入数组
with open('C:/Users/lyl/Desktop/kechuang/original_file/all.txt', 'r', encoding='utf-8') as file:
for line in file:
data_all.append(line.strip())
def save_data_name(datas, year, flag):
# 打开文本选择写模式,并指定编码格式
b = 0
file = open('C:/Users/lyl/Desktop/kechuang/{}_{}.txt'.format(year, flag), 'w', encoding='utf-8')
# 不能直接写入list,所以通过遍历一条条写入
for data in datas:
# print(data)
matches = re.findall(re.compile(r'(\b\d{4}\b)/\d{2}/\d{2}'), data)#正则表达式匹配
if matches:
if str(re.findall(re.compile(r'(\b\d{4}\b)/\d{2}/\d{2}'), data)[0]) == str(year):
# print(re.findall(re.compile(r'(\b\d{4}\b)/\d{2}/\d{2}'), data)[0])
if flag == 1:
file.write(datas[b + 1] + '\n')
else:
file.write(datas[b + 1] + ' ')
# print(datas[b+1])
b += 1
# file.write('----------------------------------' + '\n')
file.close()只获取年份就ok了。分别写两个文件,一个是一个标题一行的,另外一个是不分行,不同文章标题只加个空格。
完整源代码和执行效果:
#有些库缺失的自行下载,有些不是必要的库
from bs4 import BeautifulSoup
import requests
from lxml import etree
import csv
import time
import re
import urllib.request as req
import xlwt
import threading
import traceback
import logging
#正则表达式匹配
find_time = re.compile(r'data-time-type="fromNow" data-type="nkcTimestamp" title="(..........)')
find_name = re.compile(r'<div class="article-panel-title"><a class="article-panel-tit.*?<span.*?>([\s\S]*?)</span></a>')
find_synopsis = re.compile(r'<div class="article-panel-abstract"><a href="/t/.*?" target="_blank">([\s\S]*?)</a></div>')
find_serial = re.compile(r'data-article-tid="(.*?)"')
#一个list,后面读取数据和处理数据要用到
data_all = []
data_list = []
i_num=0
#60 970
def set_film(file, content):
#这是防止有些内容是空的,就会报错,先判断是否非空
# 检查查找内容的长度,如果不为0,说明查找到内容,则将内容转换成字符串类型
if len(re.findall(file, content)) != 0:
film = str(re.findall(file, content)[0])
else:
film = "--空--"
return film
#请求头,可以带入cookis因为有些网站需要登录才能查看内容
headers = {
"Cookie":"userInfo=xxxxxxxx; userInfo.sig=xxxxxxxxx"
# "User-Agent":"Mozilla/5.0 (Windows NT 10.0; Win64; x64) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/120.0.0.0 Safari/537.36 Edg/120.0.0.0"
}
#把获取到的数据写入.txt方便后续二次处理
def save_data_txt(datas, save_file):
# 打开文本选择写模式,并指定编码格式
file = open(save_file, 'w', encoding='utf-8')
# 不能直接写入list,所以通过遍历一条条写入
for data in datas:
for dat in data:
file.write(dat + '\n')
file.write('--next--' + '\n')
file.close()
def set_font(bold, size, horz):
# 创建xlwt格式对象
style_font = xlwt.XFStyle()
# 设置字体是否为粗体
style_font.font.bold = bold
# 设置字体尺寸大小
style_font.font.height = size
# 字体是否居中
if horz:
# 设置字体水平居中
style_font.alignment.horz = 0x02
# 设置字体垂直居中
style_font.alignment.vert = 0x01
# 设置单元格自动换行
style_font.alignment.wrap = False
# 返回设置的字体样式
return style_font
# 保存数据到excel文件中
def save_data_excel(datas, save_path):
# 创建一个xlwt对象,使用utf-8编码格式
excel = xlwt.Workbook(encoding='utf-8')
# 创建一个工作表,命名为top250
sheet = excel.add_sheet('kechuang')
# 设置列的列宽
width_c = [256*15, 256*40, 256*10, 256*2560]
for i in range(0, 3):
sheet.col(i).width = width_c[i]
# 设置三种单元格样式 set_font(粗体,尺寸,居中)
style_font_title = set_font(True, 240, True)
style_font_content = set_font(False, 220, True)
style_font_content1 = set_font(False, 220, False)
# 表格各列的列名
titles = ['time', 'name', 'serial', 'synopsis']
index = 0
# 将标题写入excel
for title in titles:
# (单元格行序号,单元格列序号,单元格的内容,单元格样式)
sheet.write(0, index, title, style_font_title)
index += 1
# 将数据写入excel
index_r = 1
for data in datas:
index_c = 0
for item in data:
sheet.write(index_r, index_c, item, style_font_content1)
index_c += 1
index_r += 1
# 保存excel文件到指定路径
excel.save(save_path)
#爬虫主体,使用了多线程,但没有使用锁,因为数据乱序不影响制作词云图
def down_task(task_num):
global i_num
try:
for i in range(0, 1220, 10):
i_num = i
response = requests.get(f"https://www.kechuang.org/c/new?page={i+task_num}&t=thread&s=toc", headers = headers, timeout = 20)
time.sleep(0.5)
html = response.text
time.sleep(0.5)
# 接下来是逐一解析数据
bs = BeautifulSoup(html, 'html.parser')
# 使用标签 + 属性组合查找,查找<div class="item"></div>的标签块
f_list = bs.find_all('div', attrs={"class": "articles-panel-item style-abstract"})
# print(f_list)
for f in f_list:
data = []
# 将正则表达式提取的内容赋值给自定义变量
fine_time = set_film(find_time, str(f))
file_name = set_film(find_name, str(f))
fine_synopsis = set_film(find_synopsis, str(f))
fine_serial = set_film(find_serial, str(f))
# 将所有需要的数据保存到data列表
data.append(fine_time)
data.append(file_name)
data.append(fine_serial+' '+str(i+task_num))
data.append(fine_synopsis)
# 写入data(单条文章信息)列表,到总的 data_list(所有文章信息)列表
data_list.append(data)
print(data)
response.close()
except:
file = open('C:/Users/lyl/Desktop/kechuang/original_file/error.txt', 'w', encoding='utf-8')
file.write('error' + " {} {}".format(i_num,task_num) + '\n')#指示报错的线程和页码
file.close()
errorFile = open('log.txt', 'a')
traceback.print_exc()
errorFile.write(traceback.format_exc() + '\n')
errorFile.close()
def save_data_name(datas, year, flag):
# 打开文本选择写模式,并指定编码格式
b = 0
file = open('C:/Users/lyl/Desktop/kechuang/{}_{}.txt'.format(year, flag), 'w', encoding='utf-8')
# 不能直接写入list,所以通过遍历一条条写入
for data in datas:
# print(data)
matches = re.findall(re.compile(r'(\b\d{4}\b)/\d{2}/\d{2}'), data)
if matches:
if str(re.findall(re.compile(r'(\b\d{4}\b)/\d{2}/\d{2}'), data)[0]) == str(year):
# print(re.findall(re.compile(r'(\b\d{4}\b)/\d{2}/\d{2}'), data)[0])
if flag == 1:
file.write(datas[b + 1] + '\n')
else:
file.write(datas[b + 1] + ' ')
# print(datas[b+1])
b += 1
# file.write('----------------------------------' + '\n')
file.close()
def read_data_in_list():
with open('C:/Users/lyl/Desktop/kechuang/original_file/all.txt', 'r', encoding='utf-8') as file:
for line in file:
data_all.append(line.strip())
#开始计时
start1 = time.time()
thread_list = []
#创建10条线程并发下载,要不然太慢了,但也不能多,dos攻击封ip了
for i in range(0, 10):
thread = threading.Thread(target=down_task, args=[i])#args传入参数
thread.start()
thread_list.append(thread)
for t in thread_list:
t.join()
save_excel_path = 'C:/Users/lyl/Desktop/kechuang/original_file/all.xls'
save_data_excel(data_list, save_excel_path)
save_txt_path = 'C:/Users/lyl/Desktop/kechuang/original_file/all.txt'
save_data_txt(data_list, save_txt_path)
#数据处理,建议先注释掉数据处理的,数据爬取和数据处理分开进行
read_data_in_list()
for year in range(2005, 2025):#按年份把标题分开
save_data_name(data_all, year, 1)
save_data_name(data_all, year, 0)
end1 = time.time()
print("耗时", end1-start1, "秒")结果:






(图片中的文本如果不允许显示,烦请管理员删除)

回到我们的目的,制作词云图。
开始是计划使用jieba库进行分词,分词后手搓词云图,下面是测试一下之前写的文章的分词效果,分别使用TextRank算法和TF-IDF算法分词,
import jieba
import jieba.analyse
text = """
前言:
闲来无事,比赛也比完了,最近摸摸鱼,搞点之前一直想搞但又没时间搞的,这个当代艺术驱动器还是很有意思的,源工程是使用STC芯片,我换STM32了。
主要特色&可玩性:
1、使用STM32F103C8T6(C6T6也是通用的),去掉外围晶振电路,直接使用内部时钟。这一步停了挺久,我当时认为要设置参数那些,其实是不用的,STM32开始就是使用内部时钟,识别(这个词不一定准确)不到外部时钟会继续使用内部时钟。至于时序倒不用担心,我串口通信115200都没有问题,主打就是省电和尽可能减少外部器件。
2、优化布局,把大多数元器件隐藏到OLED屏幕下面,留出位置加图片和艺术字。
3、优化字库芯片算法(参考的开源文件里面关于字库芯片取字留了一手,导致取出的字是乱码)。务必注意购买的字库芯片的型号,GT20L16P1Y和S1Y的选址是完全不一样的,当时我就是被这里坑了。本工程使用的是GT20L16P1Y。
4、为了节省空间和美观,使用安卓线接烧录器烧录,USB公头抽四根线出来就行,挺方便的。使用过0.5排线座接烧录器和烧录探针烧录的方法,前者焊接连锡太痛苦,刮锡搞半天,后者调试的时候不稳,卒舍弃。
5、显示你喜欢的句子or单词、短语,中英文皆可,按键随机切换到下一个(目前是使用定时器取余伪随机)。
6、带两个LED灯。
7、带金属化过孔,可以当做挂件装饰。
后续优化:
1、可以插入简单的开机动画,64K FLASH容量够大。
2、目前在想办法省电,CR1220电池能撑个几小时,如果换可冲电池又太贵了,电路也要重新搞。突然想到,可以接个io口出来使用STM32推挽模式PWM(能有几十毫安电流,按照0.1C充电,5mA左右的充电电流)+ADC采样电阻电压(获得电流)约等于电池充电管理。貌似又没必要这么麻烦,直接接AMS1117的3.3V输出然后加个恒流二极管充电得了。
3、简版谷歌小恐龙游戏,自带一个按键(有硬件消抖),基本的跳起是没问题的。 电池根本撑不住哇。
4、显示图片(例如二维码(我使用的是草料二维码,经验证,32*32插个活码网址进去没问题,静态文本几句英文也是足够的)二维码能插入很多有意思的,比如说一段文字,或者重定位到小程序对喜欢的女生表白【滑稽】)。
5、后续可以换成TFT屏幕,更便宜,分辨率更高,还是彩色的,但耗电也是个问题。 这个也是别想了,电池根本撑不住
后续测试过程中的问题:
功耗实在是太厉害了,芯片如果不进入停止模式,电流去到5mA左右,加上字库芯片工作电流4mA,OLED屏幕4mA,CR1220电池压根撑不住,电压拉下来显示很容易出错。缓解方法是降低OLED的显示亮度和降低屏幕的时钟分频比(0xd5寄存器)以及芯片进入停止模式(OLED照常显示),按键中断重新进入工作模式,刷新完显示之后重新进入停止模式。
调试到后面工作电流是12mA左右(持续1s左右),待机电流是2mA左右(左右是因为OLED显示的字越多耗电越多,只能给出一个大致范围)。
"""
seg_list = jieba.analyse.extract_tags(text, topK=10, withWeight=True, allowPOS=('n'))
print(seg_list)
#[('芯片', 0.516556270197869), ('时钟', 0.38438069979221307), ('字库', 0.38371977293770493), ('电流', 0.3705347805363935), ('电池', 0.36978008038868854), ('屏幕', 0.28956634261508196), ('二维码', 0.2530268788352459), ('模式', 0.2471521190782787), ('按键', 0.23009957876336065), ('烧录器', 0.1959797951295082)]
seg_list = jieba.analyse.textrank(text, topK=10, withWeight=True, allowPOS=('n'))
print(seg_list)
#[('问题', 1.0), ('芯片', 0.9689175521290091), ('字库', 0.669291929954668), ('电流', 0.6560958075434182), ('烧录器', 0.5667999212063058), ('屏幕', 0.5546570601311374), ('游戏', 0.4640190069252803), ('二维码', 0.4578109380139069), ('按键', 0.45591698576626244), ('程序', 0.424226261031158)]可以看到,分词效果还是不错的,细细一想,我给他的数据是关联系较弱的标题文本,下面是两个算法的优势和局限
TF-IDF算法优势:TF-IDF算法能够帮助识别在特定文档中重要但在整个文档集合中不那么常见的词汇。这对于突出每篇文章目录中独特且有区分度的关键词很有帮助。局限性:如果目录之间的差异非常大,TF-IDF可能会倾向于提取过于独特的词汇,从而可能忽略一些重要的通用词汇。
TextRank算法优势:TextRank不依赖于文档集合之外的信息,而是基于文本内部的词汇关系来评估词汇的重要性。它可以捕捉到目录中词汇的关系,可能更适合提取反映文档主题的关键短语。局限性:对于极其离散的目录文本,TextRank可能不如TF-IDF那样直接在找出独特词汇方面有效,因为它更侧重于通过词汇间的共现关系来评估重要性。
发现使用这两个算法不大恰当,我的文本之间的关联性不强。后面摸索一番,发现一个可以直接制作词云图的网页,只需输入文本即可自动分词制作词云图,操作非常简单。

生成一下2012年的词云图

哇!效果显著

再来生成2022年的词云图:


我宣布这是硫酸铜晶体的大胜利!

END爬虫还是很有意思的。
不足:
1、没有使用线程锁,导致数据乱序,虽然不影响制作词云图的目的,但excel表查看数据需要手动把文号降序排列才能看到按时间发表的文章
2、如果爬取过程中某条线程Error,该线程会自己停下,不爬取该线程后续应当爬取的数据,造成数据缺失。如果出现了报错,得从头重新抓取数据。
ps:前5有kcb,文章定有不少错误,欢迎各位指出。
pps:建议先把数据离线到本地(.txt之类的)再数据处理,两步分开完成
[修改于 6个月24天前 - 2024/07/29 11:56:56]
看到跟计算机有关的,本noip蒻驹必须顶一个(dog)
看不出有什么错误,可能是我不懂python和爬虫吧。写得很好,通俗易懂,完整性和实用性在我近期看过的文章中是独一无二的。kc这种公益网站应该没什么禁忌吧,估计爬不到多少有商业价值的信息。
kc币就不用了,好帖该有的样子,赞。
楼主润了吗。帮忙想想,假设是N台肉鸡IP不重复的实施楼主的操作,应该如何识别并拦截?
现实是,大约有90多家爬虫(其中相当数量估测为AI公司)每天都来爬KC,并学会了检查新帖。每天有数万次访问是爬虫贡献的。但这种“攻击”非常难屏蔽,毕竟对方也采用各种手段伪装成正常访问。
楼主润了吗。帮忙想想,假设是N台肉鸡IP不重复的实施楼主的操作,应该如何识别并拦截?😂现实是,大约...
XXXXXXXXX 可以查询IP是住宅IP还是服务器IP 检测到是非住宅ip 就加一道验证 (有成本的就是去购买其API,0成本就去找找看有没有什么主流服务商的ASN列表合集, 也能过滤掉一部分) XXXXXXXXXXXXX 可以查看其IP被投诉的记录(看api好像一样可以判断IP类型),有一大堆蜜罐捕获到了网页访问请求就报告的,理论上也可以过滤掉一大堆没有针对性的全网爬虫.
当然还有个炒鸡简单的 加一大堆蜜罐目录,网页,正常访问看不见的,如果是单纯的遍历数字的爬虫如
XXXXXXXXXXXXXXXXXXXXXXXX/t/*** (t/123 正常页面 t/124蜜罐帖子网页(确保此链接正常人不能从任何地方知晓,那么很显然,访问的就是爬虫了) t/125正常页面
或者 假设现在最新的帖子就是7654,很显然除非你手动改url,否则你按什么地方都不会跳转到超过这个数字的url, , 结果有个访问7655,8888的 那很显然的不对)
XXXXXXXXXXXXXXXXXXXXXXXX/c/new?page=**&t=thread (如上)
又或者爬虫写的是(读取href=" 和 " 中间的链接)
<div class="article-panel-title"><a class="article-panel-title-content" href="
/t/89831
" target="_blank"><span>易点燃的铝热剂</span></a>给网页加个
<!-- <div class="article-panel-title"><a class="article-panel-title-content" href="
/t/8888888" target="_blank"><span>易点燃的啊米诺斯</span></a> -->根本不影响任何人的正常浏览,因为这个是注释, 网页不会渲染这个, 但是爬虫会正常触发他的检测特征 (读取href=" 和 " 中间的链接,然后访问这个链接)
不需要识别爬虫 只需爬虫无法读取那更多办法了

楼主润了吗。帮忙想想,假设是N台肉鸡IP不重复的实施楼主的操作,应该如何识别并拦截?😂现实是,大约...
还有一种方法,kc可以搞点人机识别之类的东西,稍微用点方法应该就能很容易区分kcer和爬虫了,如果是无脑的游客kc也没必要放他们进来
预防恶性爬虫,原理上不难。
粗暴型:限制单独一个ID/IP在特定时间内发起请求次数。例如登录ID限制2秒1次,匿名游客限制15秒1次
支持lz







200字以内,仅用于支线交流,主线讨论请采用回复功能。