加载中
加载中
表情图片
评为精选
鼓励
加载中...
文件下载
加载中...
拿到了
祭出凸优化中神挡杀神,佛挡杀佛的梯度下降法(gradient descent)。
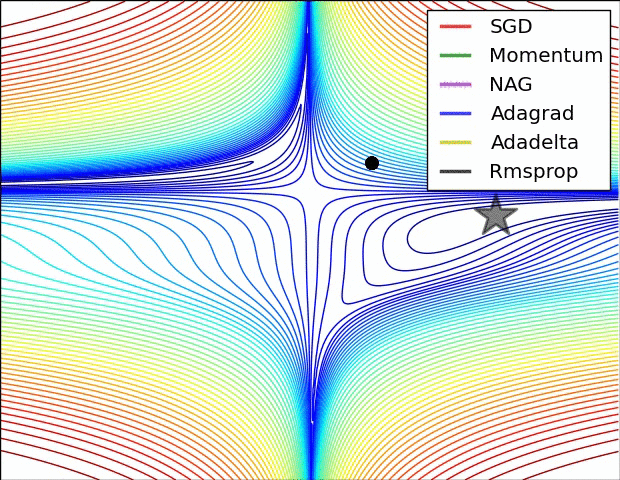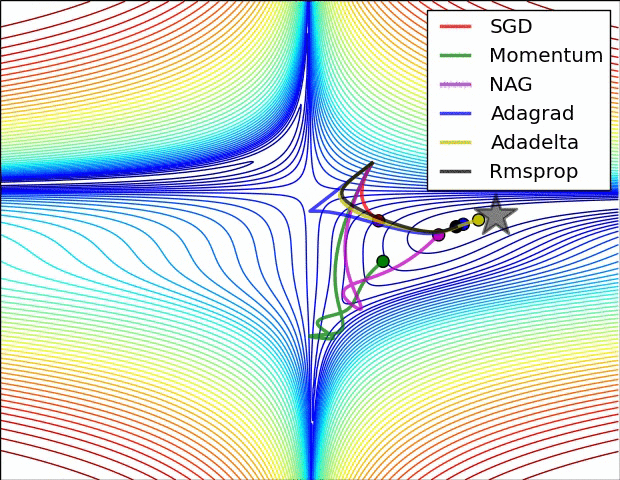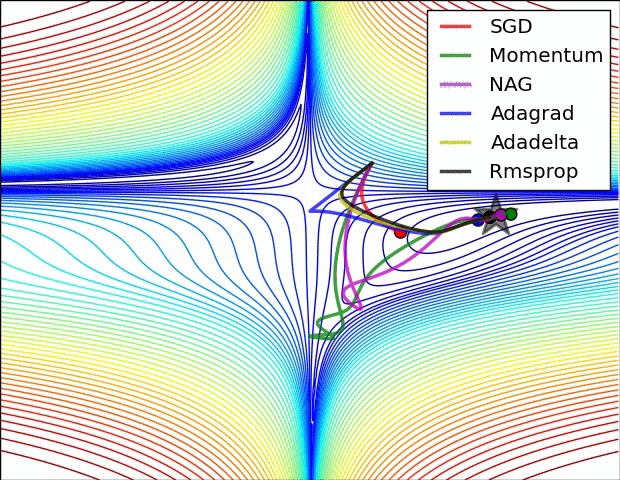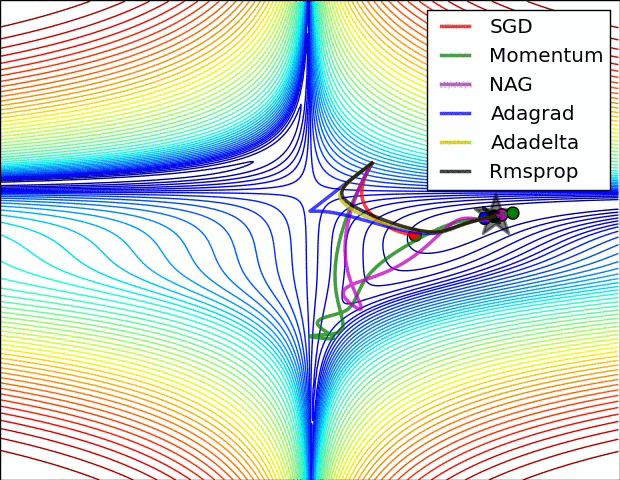
图片来源
思路简单说就是,虽然我不知道w取坐标轴上什么位置好,但我可以一小步一小步的挪过去,每挪一步都向着当前所在位置坡度最陡的地方去。于是我们就这样慢慢的圆润的滚道谷底了。
可以证明,“坡度最陡”的方向,就是该点导数方向的反方向,这本书的这个章节有极好的详述。于是我们要对
在实际程序中,我们只需要算出每个数据点对应的
但是这样真的好吗?
首先训练集的数据量一般都非常大,达到成千上万的地步,对如此大的数组频繁反复求和从计算的角度讲是非常不利的。其次,更重要的一点,我们无法保证整个数据集的数据都是有效数据,其中必然包含噪声,而把这些噪声算入我们每次计算的导数中,是非常危险的。
于是,这里我们使用另一个思路(所以我觉得机器学习里边的方法论实在是占据太多地盘了。。),每次求导时从整个数据集中随机抽取一小部分数据,用这一小部分数据作为样本来计算导数
这就是在各种机器学习算法中一路通杀的大名鼎鼎的 stochastic gradient descent,简称SGD,这种形式也叫 mini batch 法。无论是简单如Logistic regression,还是复杂如深度学习网络,优化思路基本上都是用SGD,或者说没有脱离SGD的模子。




